Accounts target architecture
Prerequisites
N/A
Reference Documents
Problem Description
Accounts domain is being decommissioned from deprecated systems and there is no documentation to align developments nor guidance to speed up project designs.
Background
First implementation of client and internal accounts was developed inside BOS on models BankAccount and BankAccountMask.
Those models got deprecated by the creation of a new service called "Account detail service" (ADS). This service is meant to store the data about client and company internal accounts.
ADS was implemented as an HTTP API using FastAPI and publishing event state transfer for all CRUD operations happening in the services. Those events are published synchronously within the API calls, perhaps if it fails, it simply logs an error and continue, no alarms/notifications raised.
BOS use the deprecated models BankAccount and BankAccountMask in several functionalities: HTTP frontal, celery tasks and daemons. Replacing the usage of the models at once it was as massive effort. So, it was decided to create a consumer from the event state transformer form ADS filling those models for retro-compatibility. Some processes have been replaced and other not, so we are now in a midterm where it is hard to determine if the processing is using BOS legacy models or ADS.
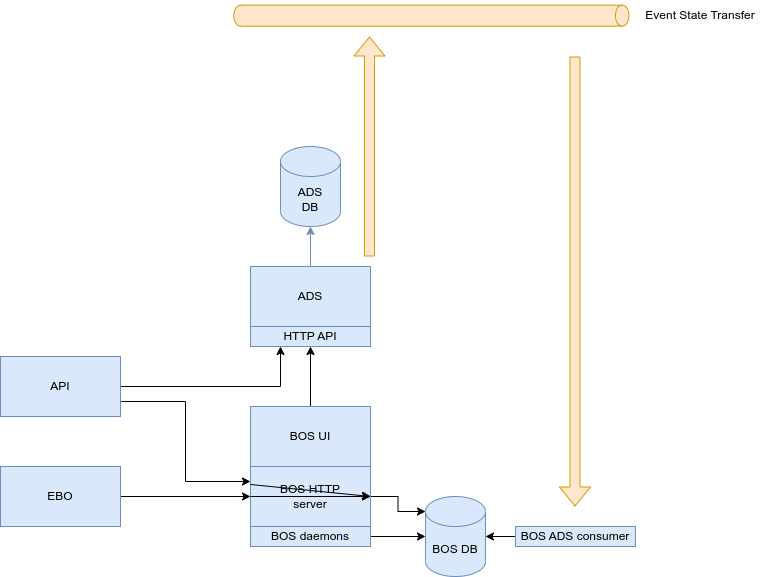
Component blue-print for it:
- https://blueprints.ebury.rocks/components/account-details/arch-accounts/
- https://blueprints.ebury.rocks/components/account-details/arch-capabilities/
- https://blueprints.ebury.rocks/components/account-details/internal-account-db-models/
Solution
Essentially keep what we have making it explicit in this document:
- ADS will be our service to store and manage the lifecycle (creation, updates...) of client and company internal accounts.
- ADS will publish Event-Carried State Transfer for other domains to be able to aggregate accounts data into its domain following reference data service .
- ADS will guarantee that event state transfer is publish (e.g. transaction outbox pattern).
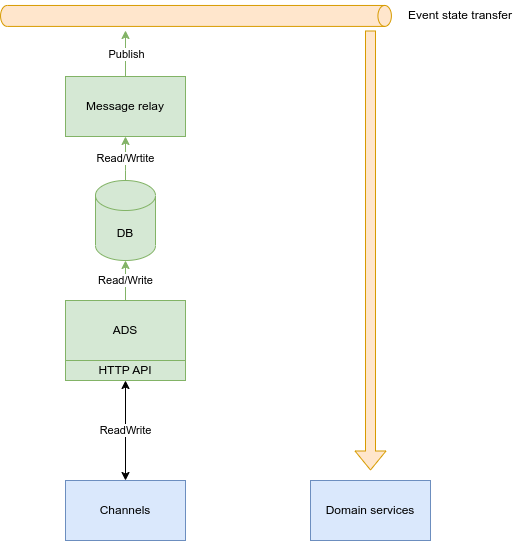
Notes:
- To ensure the events are published, transactional outbox pattern or similar pattern will be implemented.
- Strategies for sharing data with other domains will be implemented as proposed in the overall architecture. Nowadays:
- Reference data service: Event state transfer will happen in a form that then can be stored and compacted in a Kafka topic with infinite retention.
- If this strategy change or news appear, we will need to re-evaluate and eventually move the service and subscribed to a different implementation.
Accounts usage implementation
Internal accounts and clients accounts has different usages over Ebury platform. The usage of the accounts is outside accounts domain. Each domain will need to implement their solution for accounts usage.
Example source accounts (not real, just for clarification):
- When we send a payment using GBP from the UK to the UK, then the FasterPayment (FPS) is selected as payment instrument and Barclays UK as intermediary bank.
- OPS will query "Source account service" with the payment with payment routing results.
- "Source account service" is subscribed to ADS events and stores all internal accounts in their database.
- "Source account service" offers an operations UI where an operations team member has store a rules with FPS + Barclays Uk to be selecting account GB12341234.
- OPS request "Source account service" with payment information and get the response GB12341234 as source account
- OPS fills that data into the payment information and publish an event about it.
All the "source accounts" usage is store in the payments domain, ADS is not aware of it.
Example
Imagine this scenario: * We have ADS publishing event state transfer in Kafka since 2020. * The events in kafka has a retention policy of 7 days. * We create a new service that needs to know if an internal account exist looking by their IBAN. * We never changed any internal account since 2022, so there is no events about internal accounts in Kafka.
How do we transfer all current accounts to the new service? The infinite retention proposed in "Reference data service" is meant to do so. If we have infinite retention, once we start the event consumer in the new service, it will start processing events from the beginning. This will create all entities into the new service.
Alternatively, we can build one-off scripts getting data form the API or from a database dump. Also, we can build a system that replay (re-queue) all events in ADS.
Alternatives
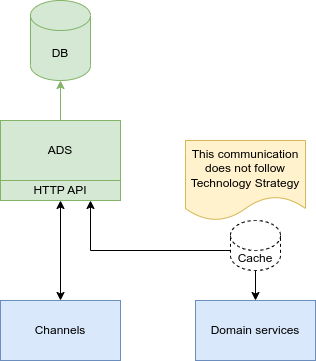
Alternative 1: HTTP API + optional cache
This version meant to have all services connecting to the ADS and optionally caching the data.
This version is described here because of the simplicity, but it is not following technology strategy. So, discarded as an option.
Alternative 2: Different service for client and internal
This version proposes same as solution but creating 2 services, one for client accounts and another for internal accounts.
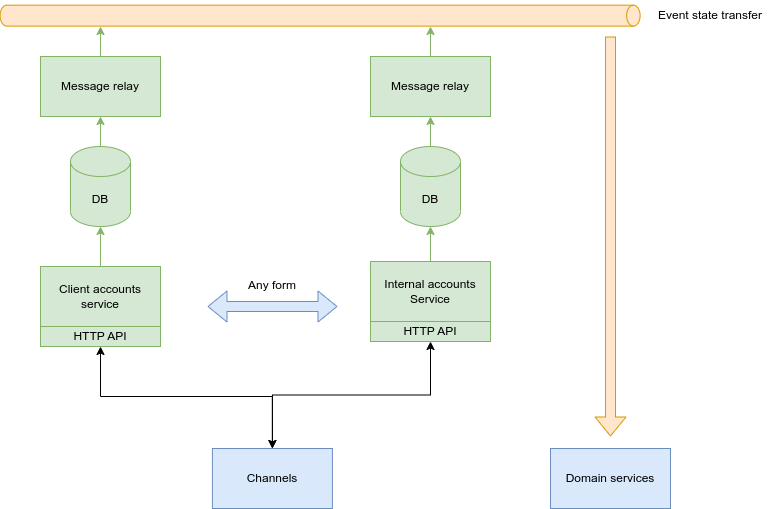
Pros:
- As such small scope in services, it is:
- Easier to change them.
- Smaller single point of failure.
- Modeling in both service can be tun-up for special reading/written needs: Client will be used more frequently than internals.
Cons:
- Complexity in communications between the services.
- Potential couple code between them, as client and internal accounts are very related.
- Hard to share common functionality (IBAN validations, local bank account structures, etc).
- We have to do the split. Currently, both are in the same service.
Caveats
Infinite retention topics
This is problematic at infrastructure level:
- Infinite retention have unbounded growth, even more if we don't have compaction.
- We are still testing how compaction works, we are still not mature enough to have all the insights.
- The compaction may add extra complexity and potentially development in terms of messages publishing order. Currently, ADS does not guarantee events are published in order.
If so, we prefer to not have infinite retention, it is possible implement an alternative for initial data load, e.g:
- Request the HTTP API for the initial load.
- Offer a mechanism to replay all events.
- Use database dumps/backups as initial load.
Client accounts reads/writes increase a lot vs internal accounts
We may need to improve performance for client accounts. If we do tun-ups to increase performance that add complexity, then that complexity may be add in internal accounts as well. Perhaps, trying to solve this nowadays it is a pre-optimization problem .
Operation
N/A
Security Impact
N/A
Performance Impact
Having all client and internal accounts are living in the same server and requested by the same HTTP server, so it may be a bottleneck. Check caveats section.
Sample of requests counts in July 2023:
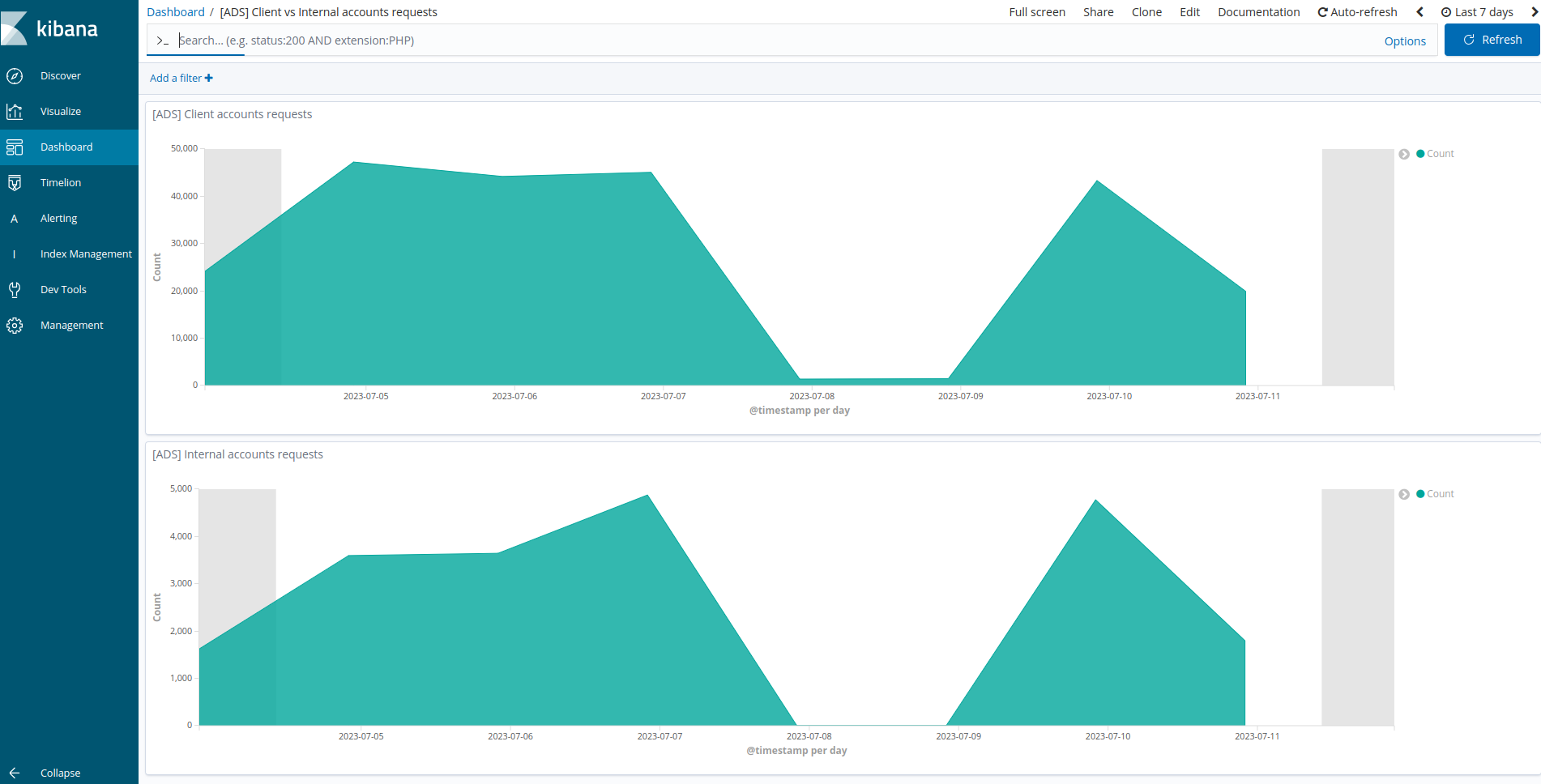
The clients are in the order of tens of thousands and internal in thousands so like x10 usage for client accounts.
Developer Impact
Some few improvement/refactor will be need to run over ADS.
Data Contracts
N/A
Deployment
N/A
Dependencies
N/A
Based on RFC Template Version 1.1