Frontend Architecture for BOS Operations Dashboard
A high level architecture proposal for the BOS Operations Dashboard as part of "Ebury 2.0".
The Operations Dashboard is a mixture of server rendered views with some jQuery and Backbone/Marionette client-side widgets serving a mixture of Django rendered views and client-side templated views.
The existing frontend is built via a Django staticfiles application.
This RFC is intentionally terse, however there is a prototype of most of the concepts discussed available at https://github.com/ebury/Bosporus
Problem Description
BOS will be likely to see significant changes in the near future, due to performance related refactoring and the Ebury 2.0 project to split BOS into microservices.
Currently, changes to BOS data usually mean changes to BOS views.
In order to allow the Operations Dashboard, APIs and service architecture to develop at their own pace, we need to further decouple views from models and controllers beyond what Django allows.
In addition, BOS frontend "stack" is outdated, inefficient to work with and offers a very poor developer experience.
Solution
Decouple the user interface layer from BOS using a Backend for Frontend (BFF) architectural pattern with GraphQL as the implementing framework.
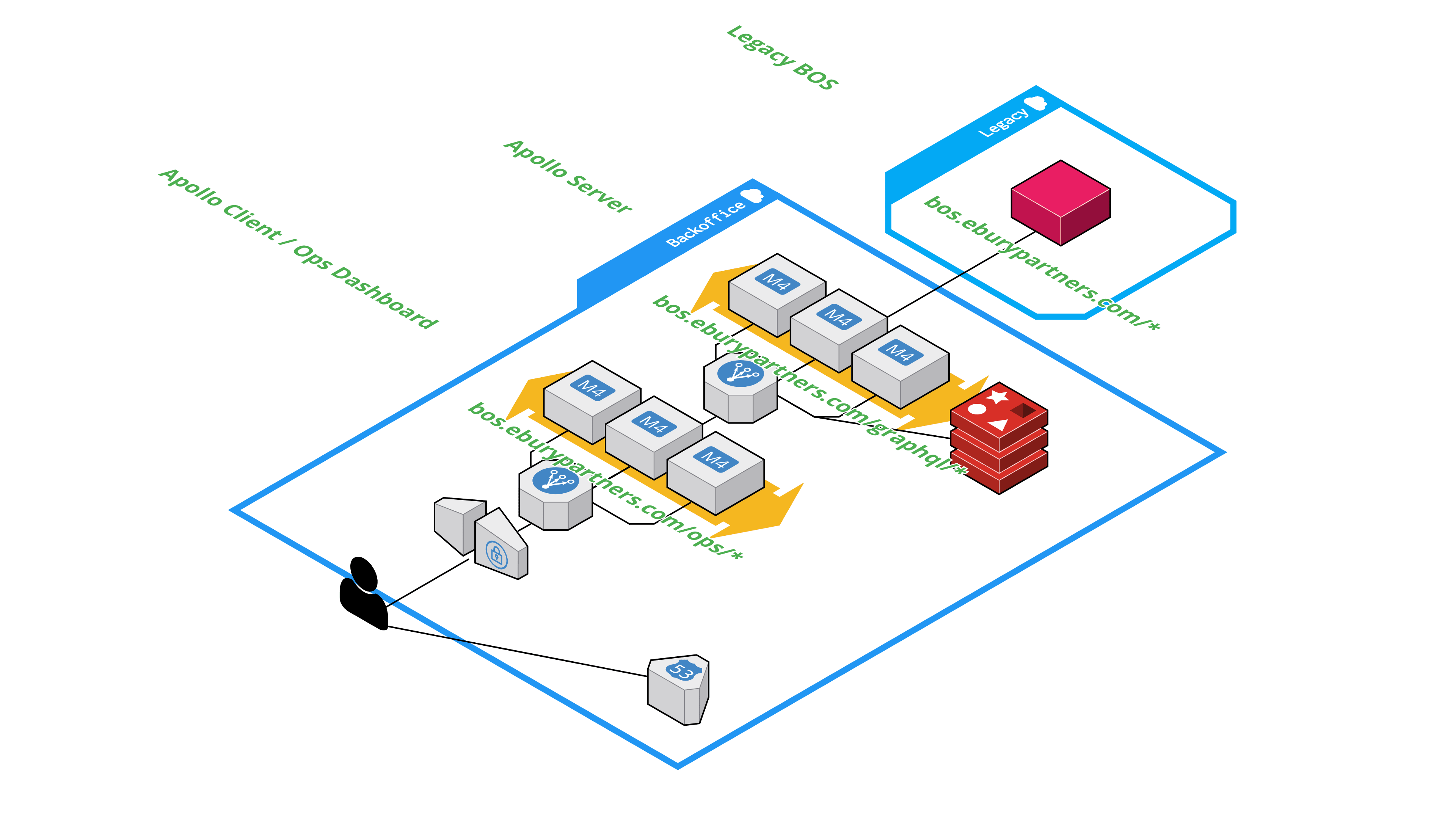
This proposal introduces a new Operations Dashboard in a standalone service which communicates with BOS services via a thin API and routing layer (the BFF). This BFF is enabled by Apollo Server (Node.js; but any GraphQL server works here, in any language), an open-source spec compliant GraphQL server compatible with any GraphQL client. GraphQL can unify and rationalise BOS data for the Operations Dashboard and help decouple BOS from user interface concerns.
The BFF initially layers GraphQL over REST, with ad hoc endpoints for resolvers, however this is only as an interim step in order to decouple work on Bosporus from the rest of the Ebury 2.0 project and should not be considered the pattern for connecting future Ebury 2.0 micro-services.
The architecture is flexible on the method of communication between GraphQL server and data source (e.g. gRPC, SQL, WebSocket, etc). gRPC allows automatic generation of GraphQL Schemas from protocol buffers and is a recommended practice for connecting services in Ebury (https://blueprints.ebury.rocks/practices/protobuf-and-grpc-stack/).
This proposal co-locates schemas on the BFF, but eventually, with Apollo Server, schema definition can be federated to individual services and co-located in those code repositories. Schema stitching is an alternative method of managing a distributed graph. An RFC to discuss the choices here should be presented at a later date. (AKA We'll burn that bridge when we get to it).
Reasons to choose GraphQL:
-
No request over- or under-fetching. Response returns exactly what data the asked for the request.
-
It provides a consistent and well-understood API with a great dev UX (API, spec, docs, etc) and lots of community support & tooling
-
Ebury already has some experience with GraphQL, it's used by the PRI team to expose webhooks API to the end user (https://docs.ebury.io/#webhook-notifications).
-
Forces us to think about shape of data from a product perspective, as a piece, rather than in an ad hoc manner.
This solution gives us a modern frontend stack for the Operations Dashboard which could be valuable recruiting tool for Ebury.
Alternatives
Follow the EBO model and use Django as the framework to deliver the user interface, with views becoming simple conduits to BOS (micro) services as Ebury 2.0 rolls out.
This would be an inferior solution due to the reliance on Django and REST, we would not gain the same benefits in tooling and would not likely achieve the same level of decoupling.
Caveats
n/a
Operation
There are 3 domains:
- User Interface Engineering
- Client Data Services (GraphQL schemas, resolvers)
- BOS APIs (existing and future) (REST, gRPC, SQL, etc)
Propose that initially that domains 1 & 2 belong to a new BOS multi function team that is able to work in a DevOps style.
Client Data Services group/team should ensure that the GraphQL layer is not coupled to the implementation details of either the APIs or UI, and via code review ensure consistent standards for BOS service APIs.
Project Roadmap (Helicopter view)
Clients is chosen as small, discrete part of BOS data to work with.
- Server: GraphQL Schema for a Client
- Server: Resolvers for Client Schema (investigate resolving against Salesforce directly).
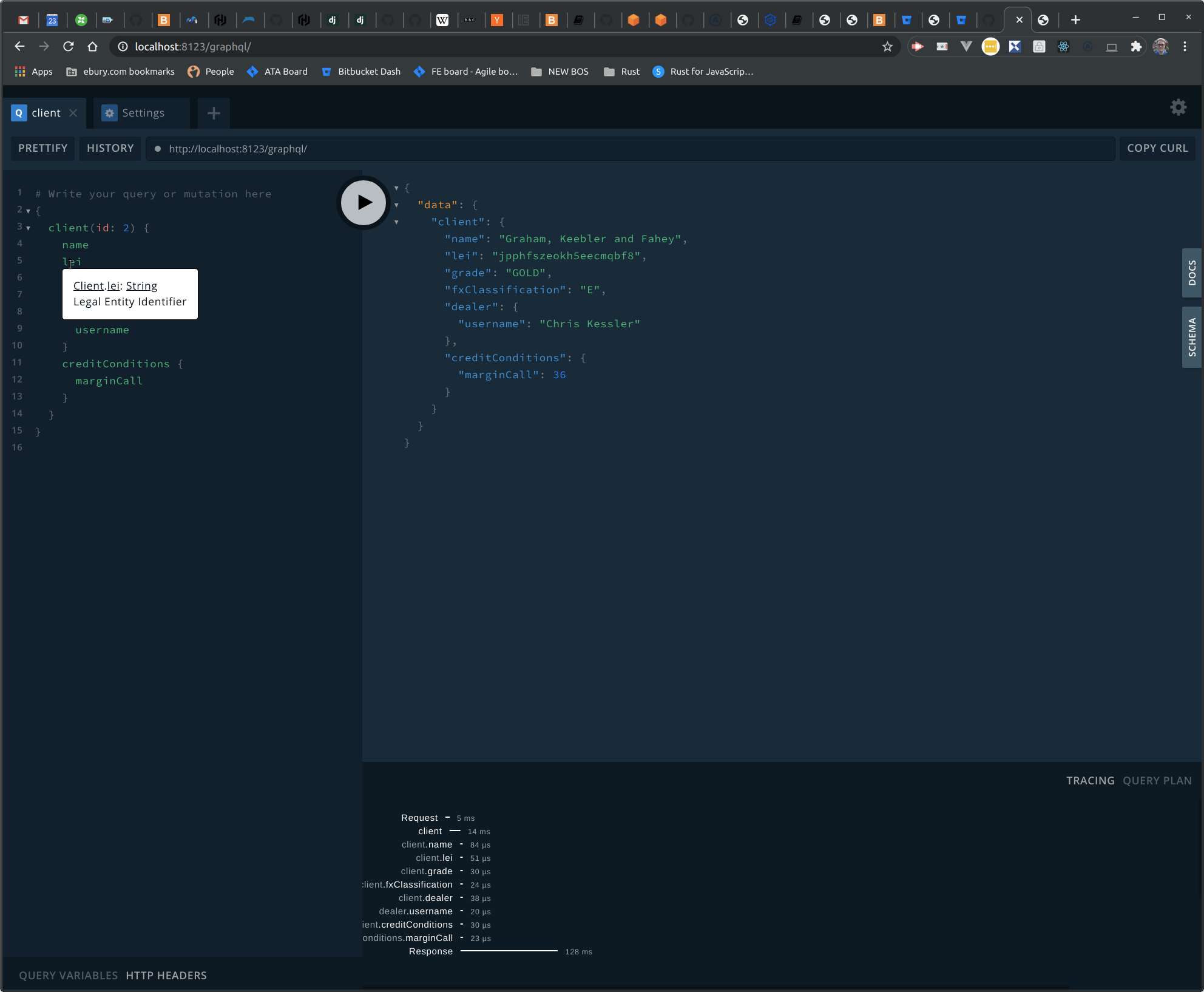
At this point we have a GraphQL Server implementation working against a single slice of "BOS data", Clients, which can be query using GraphQL IDE.
- Implement jQuery (existing BOS frontend stack) client GraphQL Query
- Simple Operations Dashboard view to search and find clients as a (possible small steps):
- Regular html view proxied via path
- Browser extension
- Portal into Django view
Security Impact
At a high level:
-
Provisioning a new node service with web server with associated secrets.
-
Provisioning a new node service with GraphQL server with associated secrets.
-
User authentication and authorization via the existing Django session authentication backend.
Performance Impact
n/a
Developer Impact
This proposal considers that the User Interface will be written in React, which is a change from Backbone/Marionette/jQuery in BOS frontend.
GraphQL is already used in Ebury, but not widely, some developers may have to grok GraphQL.
Data Consumer Impact
There are no downstream consumers of this service.
This proposal does lay the ground work for a new BOS API, either as GraphQL or using GraphQL as a proxy to REST. The scope of this RFC however is the Operations Dashboard.
Deployment
Deployment from Bitbucket repo via Jenkins, both projects are nodejs services (eburyPipelineNodeService).
There are 2 services to deploy in stages, both to the "backoffice" cluster:
-
Deployment of GraphQL Server
-
Deployment of Web Server and S3 buckets
Configuration of services will be, as per existing projects, via Terraform /Terragrunt.
Monitoring & Metrics on the GraphQL Server
Apollo Server provides a health check endpoint at
/.well-known/apollo/server-health which returns a HTTP 200 status code
if the server has started.
Fine-grained logging is made possible by defining a custom plugin. Read more on Apollo Server logging in Apollo Server documentation..
Apollo Studio
Apollo Studio is a service that integrates with Apollo Server to monitor the execution of GraphQL operations. Apollo Studio can ingest operation traces from the GraphQL server to provide performance metrics for the Bosporus data graph.
A trace corresponds to the execution of a single GraphQL operation, including a breakdown of the timing and error information for each field that's resolved as part of the operation.
Trace reporting enables visualization of:
- Which operations are being executed
- Which clients are executing which operations
- Which parts of the schema are used most
- Which resolvers in the server are acting as bottlenecks
The free tier in Apollo Studio includes performance metrics for a 24 hr period.
Apollo Studio should be trialed initially at least until the service has established a sufficient level of monitoring with Ebury's own infrastructure.
Note on AppSync
AppSync is an AWS product which essentially wraps Apollo Server; however, AppSync developer experience is not great. AppSync uses Apache Velocity Template Language for configuration, and requires LocalStack Pro in order to run in a dev env.
At this point this proposal is not recommending using AppSync.
Dependencies
n/a