Ebury 2.0 Beneficiary Service
Problem Description
The Monolith Structure
BOS is a single Django Application, and consequently suffers for all the drawbacks of monolithic structures, such as :
- too large and complex to fully understand.
- difficult to change correctly.
- difficult to add new functionality.
- difficult to test.
- difficult to scale.
- tightly coupled and brittle.
- locked into specific technologies
- can only be released all at once
Poor Performance
BOS data is persisted using a relational model. Accessing the data requires a combination of object-relational mapping (ORM) to read data into Python objects and object-relational queries to filter and aggregate data for delivery in a format required by the business domain.
This process is often very expensive :
- Python objects are created on the heap for each data entity.
- The application maintains references to these objects long after they are required and memory is tied up.
- Queries can create a large number of objects - which are then filtered.
- Creating an aggregated data structure often requires a large number of sequential queries.
This leads to :
- Excessive memory use and thrashing.
- Excessive number of queries
- Duplication of effort as expensive processes are repeated on every access.
- Very poor performance.
Background
In order to migrate from the monolith and solve the poor query performance, It is proposed to create a Beneficiary Management Service outside of BOS using an event driven microservice architecture. The first phase of that ‘Minimum Viable Product’ (MVP - aka proof of concept) would be this Beneficiary Query Service based on the CQRS pattern. The second phase would be the Beneficiary Command Service, further extending the CQRS pattern.
Objectives
- To create a working reference implementation to demonstrate the CQRS and Gateway design patterns and concepts of the Ebury 2.0 event driven microservice architecture
- To validate and understand the implications of a capability/business process being provided by both BOS and a new command service concurrently to enable a phased migration of channels.
- To get a better understanding of standards, guidelines and platform level code that should be created to implement event driven microservices consistently across the engineering teams.
- To get a better understanding of our infrastructure requirements.
- To get an indication of the latency between a change being made in BOS to that change being propagated to the query service
Scope
The MVP will implement the Beneficiary Management business capability in an event driven CQRS architecture and provide API access to beneficiary information.
The first phase will:
- Provide a definitive REST API query endpoint to access a clients beneficiaries - as part of the Beneficiary Management Service.
- Provide a compatibility endpoint which is backward compatible with the 'client/beneficiaries' endpoint provided by BOS to EBO. This will wrap, or substantially reuse the definitive endpoint functionality.
The MVP will:
- Create an outbound BOS Gateway component that will determine beneficiary state changes in BOS and publish the changes as commands onto Kafka.
- Create a command side service that will execute the commands and maintain the state of the Beneficiary aggregate in its data store and publish these state changes as Domain Events.
- Create a query side service that will subscribe to Beneficiary domain events and construct a read model that will provide beneficiary information for channels to consume.
Solution
CQRS and Event Driven Microservices
The proposed solution is to implement a CQRS pattern using an event driven microservice architecture - with the first phase constructing the query service.
Data structures are maintained in a format the business domain requires (read models). Queries access this data - they are simple, lightweight and fast.
Every time the reference data changes, the read models are updated. On each change to the reference data, business logic is invoked to aggregate and recompute the query models.
Read models are optimised to support the access patterns of the use case. Different read models can be provided for different use cases.
Query Service Components

1: Beneficiaries will continue to be created/updated/deleted directly in BOS via existing channels.
2: Kafka Connect forms part of the outbound gateway publishing Create, Update and Delete (CUD) events for changes in BOS. These Change Data Capture (CDC) events are generated for the BOS data required by the Beneficiary Command Service.
3 & 4: A Beneficiary data aggregation service consumes the BOS CDC events and publishes commands to the Beneficiary Command Service. BOS Beneficiary data is stored across multiple relational tables and the CDC events mirror changes to these tables. The order in which these events are received is not defined and they must be aggregated to generate well formed commands for the Beneficiary Command Service.
5 & 6: The Beneficiary Command Service consumes and actions commands, and publishes Domain Events on successful completion. The commands can be any action that is required of the Beneficiary Command Service.
7: Domain Events are consumed and aggregated to form a read model. The read model is designed for specific use cases and optimised for those access patterns.
8: A synchronous external facing API is provided to query the read model. The queries are simple and fast as the data is precomputed to optimise read performance.
Command Service Components
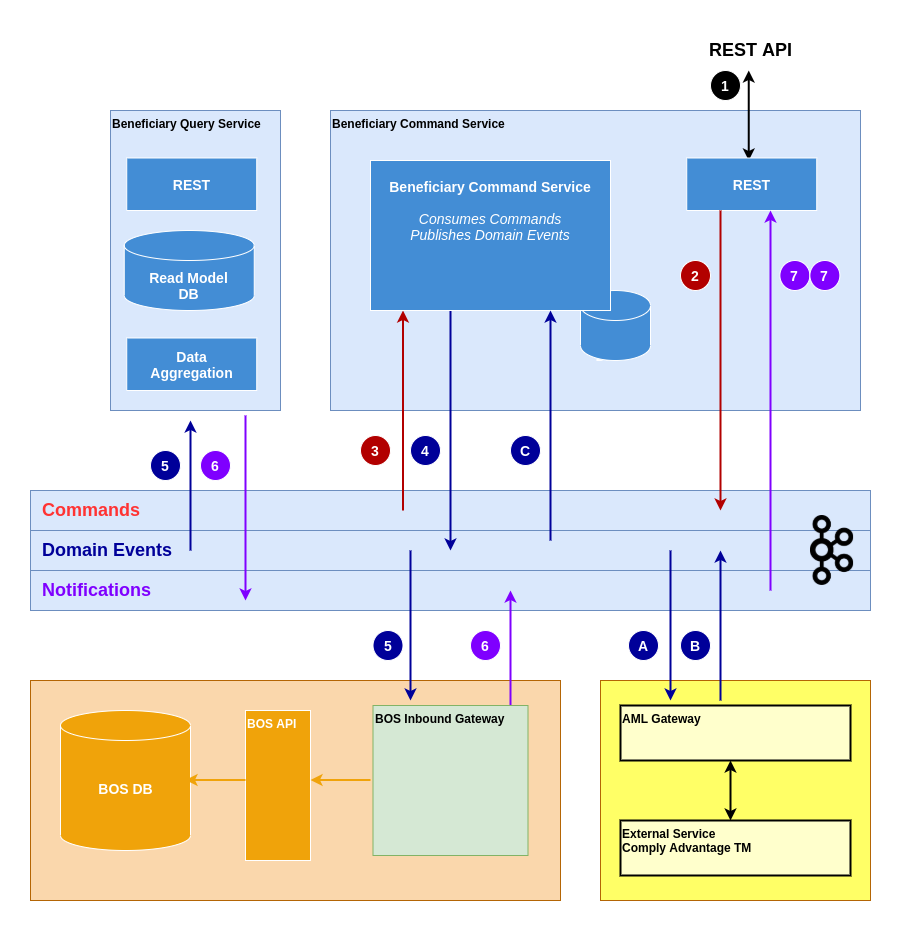
The command service forms part of the second phase and requires further analysis and detailing. The target architecture is presented here where beneficiaries are only created by the Beneficiary Command Service.
This and other patterns for incrementally migrating BOS to the Beneficiary Command Service will be covered in more detail in a subsequent RFC.
1 & 7: A synchronous API is provided to create beneficiaries. By default the creation is eventually consistent (i.e. the endpoint returns, and sometime later the beneficiary is created). However, since each model update returns a notification upon completion, strict writes can be implemented if required (i.e. only return when all models have been updated).
2 & 3: A create beneficiary command is published for actioning by the Beneficiary Command Service
4: A domain event publishing the fact that a beneficiary has been created.
5 & 6: Read models update their local representations of the beneficiary.
A, B & C: The creation process may invoke other asynchronous actions, like checking and updating the AML status.
Benefits of the Solution
The proposed solution is a step in breaking up the monolith.
The benefits of this architecture include :-
- Each service can be developed and released independently
- Each service can choose its own technology stack
- Services can be scaled independently
- Services have well defined interfaces and are self-contained
- Well defined interfaces facilitate testing
- Services are loosely coupled improving resiliency
- System functionality can be extended by creating new services.
- The complexity of a service can be constrained to be manageable by an individual or small team.
- Commands and domain events are persisted durably in Kafka. This :-
- enables the state to be rebuilt locally by read models and other services.
- enables data migration to new services
- provides an audit and debugging log of activity
- surfaces activity for monitoring
The proposed solution also significantly improves the query performance.
- The read models are optimized for queries
- Read models are structured to provide fast and simple access.
- Read models are updated every time the reference data changes.
- The precomputed data provides low latency access.
- Read models can be scaled out easily.
Alternatives
PostgreSQL Read Replicas: Scale out adding additional database read replicas to support the query workload. This brute force approach does not address the ORM or memory performance issues. It also perpetuates the monolith.
Optimised SQL: The memory use and speed of many queries could be significantly improved with hand written SQL. Whilst a pragmatic localized fix, it does nothing to help the scalability, resiliency, extensibility or maintainability of the system.
PostgreSQL Materialized Views: Are limited to data aggregation that can be expressed in PostgreSQL. They also embed business logic at a low level in the database.
Caching Query Results: E.g. in a Redis cache. Another pragmatic localized fix that relies on being able to uniquely hash query parameters and be aware of changes to the reference data that requires cache entries to be invalidated. Sometimes useful, but has limited application.
Caveats
Strict vs Eventual Consistency
The read models are eventually consistent. Updates to the underlying data will eventually result in all the read models being updated. This is the fastest and most efficient mechanism.
Strict consistency may be required in some use cases where the requestor needs a guarantee that all read models have been updated successfully. This scenario can be accommodated by waiting for the successful update notification event for each read model before returning.
CDC Aggregation
The solution assumes that the read models can be correctly and consistently updated by aggregating the CDC stream. This may not always be possible, in which case the read models need to be updated from the relevant command service, when implemented.
Security Impact
The Kafka events are encrypted in-transit (TLS) and at rest (MSK). The read model database is also encrypted at rest.
Authentication and authorisation will be done before the request reaches the query service. The solution has not been finalised, but is likely to be done through a sidecar service.
Performance Impact
Debezium and Kafka Connect are already used to implement Change Data Capture (CDC) on the database to provide real-time data feeds to the Data Team. This additional use of the CDC stream should not further impact the performance.
Read models are optimised for the data access patterns they have been designed for. The queries will be significantly faster, more efficient and use less memory than the current implementation.
Read models can be readily scaled out.
Moving queries onto the read models will reduce the load and improve the performance of BOS.
Developer Impact
The introduction of eventually consistent writes is a major conceptual change that needs to be accommodated.
New tools and development/staging environments.
The component services are in-sync with beneficiary data in BOS. If Beneficiary details are obfuscated in BOS, they are obfuscated in the component services as well.
Deployment
The first phase delivers a compatibility endpoint replicating the functionality of the 'client/beneficiaries' endpoint provided by BOS to EBO.
- Initially the compatibility endpoint will be run in parallel, processing the same queries as BOS in the production environment.
- The compatibility endpoint will be monitored for reliability, performance and correctness in comparison with BOS.
- After a period of successful parallel running, the EBO requests will be switched to the new service in such a way they can be readily switched back to BOS should there be any issues.
- After a period of successful use in production, the BOS endpoint can be retired.
Defining the infrastructure and the deployment process is one of the deliverables of this project.
Dependencies
The solution is dependent on the Debezium and Kafka Connect CDC stream.
Providing the compatibility endpoint is not dependent on changes in EBO - however EBO needs to use the endpoint to demonstrate the viability of the product.