Batch Data Delivery to Services in the Transactional Platform
Background
The “Transactional Platform” refers to the core systems and services built in house - like BOS, FXsuite and the custom built stand alone services supporting them.
Gateways connect external systems to the transactional platform.
This document describes a pattern for other Ebury systems (like the data analytics platform) to deliver batch data to the transactional platform.
The motivation for this pattern is to provide clarity, reduce friction, reduce complexity and improve productivity when implementing the delivery of batch data to the transactional platform.
Requirements
Other Ebury systems (like the data analytics platform), must be able to deliver structured batch data to a storage location shared with the transactional platform.
The data must be immutable (i.e. written only once). Subsequent updates to the data must create new versions of the data with a new identity.
Services in the transactional platform must be notified when new data is available.
Services must be able to subscribe to notifications of data coming from specific data producers.
The authenticity and integrity of the data must be guaranteed.
Producers of the data define the schema for the data. The schema enables consumers to validate the data and manage schema evolution.
Solution
The proposal is to use AWS S3 as the common storage mechanism for Ebury systems outside the transactional platform to deliver data to consuming services inside the transactional platform.
Ebury systems just create an S3 object. This service ensures that notification events with metadata are published to Kafka.
Downstream services with the necessary permissions consume the notification events and access the data from S3 directly.
Transport
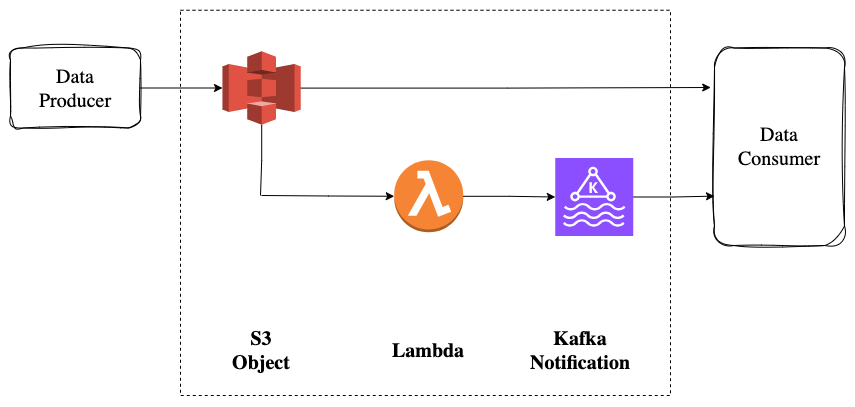
AWS S3 Object
- A data producer creates and writes to an AWS S3 object.
- The S3 object is immutable - every write with the same key creates a new version.
- Consumers must use the key and the version_id to retrieve a specific version.
AWS Lambda
- The bucket containing the S3 object is configured to trigger a lambda whenever a new S3 object is created.
- The lambda publishes a creation event to Kafka.
- The S3 URL can be used to determine the Kafka topic for the creation event.
AWS MSK
- The creation notification event contains the access URL for the S3 object
- The URL includes the bucket name, the key name and the version_id.
- Consuming services access the S3 object directly.
- The topic configuration is flexible and defined per data producer.
Immutability
The S3 object is immutable - every write with the same S3 key creates a new version. This provides an audit trail of the communications between systems on the transport level.
The content of the data however is dependent on the use case and may contain updates to specific entities.
Security
Data Producer will obtain credentials for writing in the S3 bucket by assuming an AWS IAM Role through STS. GCP is already a trusted IDP in AWS, but configuration is needed: * In GCP for the publishing workload to have an identity. * In AWS for allowing the trusted identity to write in the bucket.
Data consumers will obtain credentials from an assumed IAM role in the workload configured to read from the bucket (this is already a common pattern).
Validation
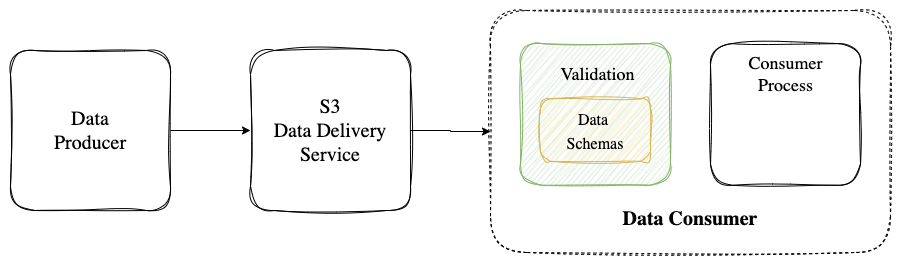
Data Validation is implemented by the consuming service.
In many cases there is only one consumer. In some cases, the validation requirements can be complex and are specific to a particular consumer.
Validation Service
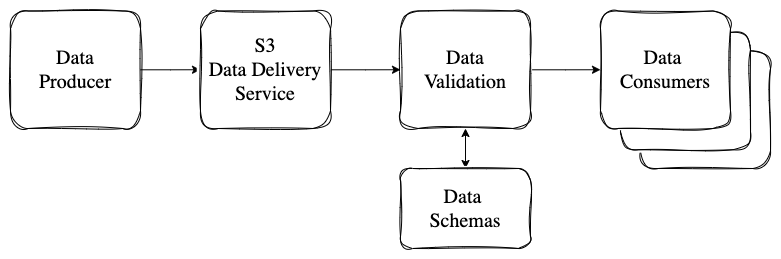
In some cases, common validation may be required before the data is consumed by multiple downstream services.
A separate service may consume the S3 creation notification from Kafka, validate the content of the S3 object against a data schema specification and publish a ‘created and validated’ event for downstream consumers.
Implementation
An example implementation would be to use benthos-lambda - a version of Benthos specifically tailored for deployment as an AWS Lambda. Benthos is a cloud native stream processor specialised in connecting different sources and sinks. The lambda would require no code - and be implemented through declarative configuration.
Alternatively, the lambda could be hand coded in Python.