Remove elasticsearch
Due to the current limitations of elasticsearch in our system, we want to remove all uses and the current dependency on it.
Problem Description
We rely on an old version of elastic:
We use django haystack on top of elastic, which has known bugs for example if we want to do a search on several models at the same time, in addition to several performance problems. On the other hand, it is not possible to upgrade haystack due to the current version of django.
Haystack, at least our implementation/usage, has coupled our precomputed data to our models, which is not very versatile. Sometimes we need to perform a transformation to present the data in a view (for example because we are showing all types of trades), and we like to have all elements indexed on the way as we are presenting that information into a view, to simplify its use but above all for performance reasons.
If in any place we use elasticsearch and we need a new field (a new column in a list for example), we need to reindex this new column in all the elements of the table, which is a long time process.
Background
On many occasions we have already talked about the unreliability that haystack presents in our system, and how extremely inefficient it is. This as one of the latest discussions
Also a CQRS system was presented in august 2019 to solve the previous problems, except the indexing time.
Solution
We can have 3 types of situations, each one with its possible solution:
Case 1. Use the django ORM directly
We can do the same with the Django ORM as what is currently done with elastic, without impairing performance or even improving it.
Case 2. Use data aggregation and materialized properties
The usage of the ORM directly is not possible (either due to its limitations or performance degradation), but the use of data aggregation is straightforward and we obtain a good performance.
In this case we will also consider the use of materialized properties (currently on early stages)
Case 3. Precompute data in queries database
As in the previous case, the use of the ORM is not possible, but adapting the code to use database aggregation and materialized properties requires large refactors or, in general, we find some technical limitation difficult to overcome that can be easily addressed through this solution.
Note
Currently the update of queries database is performed synchronously. If we found the case 3 many times, to avoid long transactions and performance problems, locks, etc. we will change the way the update is performed to asynchronous way using celery and django transaction hooks, to ensure that the commit on queries database is performed after committing on bos database and keep the consistency as it was planned on the roadmap.
Related to the previous point, in that case we would have eventual consistency, this is not a problem in the current use of queries database because the models that we currently have are to perform a quick load of certain pages and allow an eventual consistency, but for new additions to this system it will have to be taken into account.
Alternatives
The alternatives are the 3 presented in the previous point according to the criteria discussed to choose one or another.
Caveats
The queries database is basically precomputed data, so if we need a new precomputed field in that database (for example because it has been added in a new django view), we will have to update it for all the records (unless in that specific case nullable for old elements could be allowed).
Operation
NA
Security Impact
NA
Performance Impact
After the changes, the performance on the pages and / or requests that used elasticsearch should be at least what we currently have. As I mentioned before, this is one of the determining factors for choosing one of the 3 possible options to implement in each case.
The size of the queries database will be increased to a greater or lesser extent depending on the number of times we use this technology to replace elastic. But the size of queries database shouldn’t be a problem. Tables shouldn’t be containing heavy columns as it is meant for presentations in quick way, so individual tables shouldn’t be heavier than source tables.
If the accumulation of different tables is a real problem, queries app is not restricted to use a single database and the router could be adapted to use more than one database, or a different engine, or whatever needed.
Developer Impact
Since elastic is going to be removed, any changes regarding the use of elastic in BOS should be coordinated with the team in charge of removing elastic, since it has an expiration date.
Once in the maintenance phase, the parts of code that, after removing elastic, are using the queries database, and want to be extended, including a new field for example, must add that field in the queries database and update it.
Remove elasticsearch will save time in the CI, since after the execution of each test case using elasticsearch, it was necessary to completely clear the indexes.
Also, we have a lack of test coverage on a lot of views due to the limitation of our test suite using elastic, so if we implement any alternative we need to cover these views with tests. So our test coverage is going to be increased.
Data Consumer Impact
In the single source of truth that is the BOS database, the data will not change, whatever implementation is chosen in each case, so there is no impact on data consumers.
The queries database will store more information but its use is internal and surely of little interest to other systems (currently there is no consumer of this database beyond the BOS itself).
Deployment
The implementation will be carried out through parallel change, making use of feature toggling through a BosSetting to be able to progressively activate the different parts that are being updated and at the same time have a fine-grained rollback mechanism. The use of a dict type BosSetting, instead of one or more switches is justified by the following:
-
A single switch for the entire epic is not recommended because there is a lot of code that has to be activated at the same time, which is prone to errors, performance problems, etc.
-
Creating a waffle switch for each change we want to add can be too cumbersome (more likely frictions/migration conflicts with other teams adding or removing switches, deal with many items throughout the code individually but they are closely related, etc)
-
Reuse the same switch reduces the ability to work in parallel, since we need to remove the usages of the switch and perform a release to be able to reuse it.
The structure of the information BosSetting object will be (names subject to possible changes):
BosSetting
key: 'elastic_replaced'
valuetype: 'dict'
value: {
'hold_queue': 'true'
'global_search': 'true'
'overdue': 'false'
..etc..
}
As we can see, when we talk about a change, we are talking about the replacement of elastic in one part of the application, for example:
-
Hold queue page
-
Overdue page
-
Global search
Therefore, the time frame for deployment the complete epic is as follows:
Creation of BosSetting to manage feature toggling
for each feature:
create a key in BosSetting dict with false value (deactivated)
if the change is through queries database:
creation of a model in queries database
add the triggers to update that model when an element is created/updated/deleted
populate the old items through a django command
elif the change is through database viwes
creation of the view
creation of the unmanaged model
else:
perform the changes in the code to use the ORM
release all the previous code
activate feature: set the key in BosSetting to true
wait a reasonable time to ensure that the behavior is the expected one
remove the code under feature toggling deactivated state (under the key of BosSetting with false value)
Cleaning phase:
Remove the commands created to update the queries database
Remove the BosSetting that controls the feature toggling
Remove the dependencies of elastic in BOS (elasticsearch and haystack libraries)
Remove elasticsearch from BOS infrastructure
Here we can see graphically the steps that we need to perform for each feature to ensure a rollback plan:
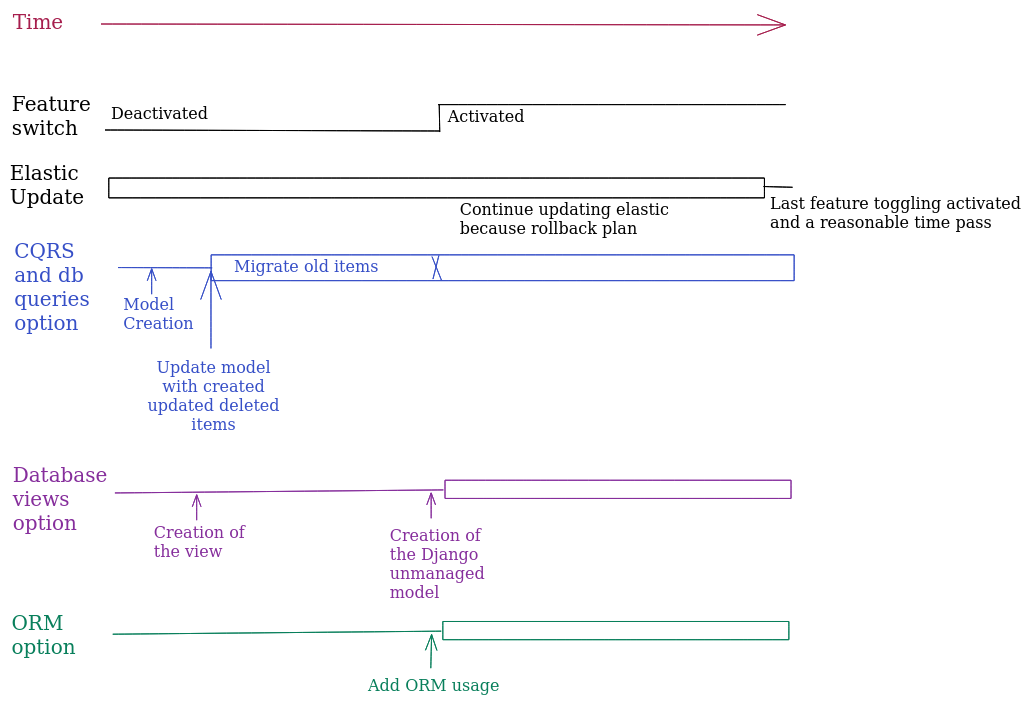
The comments with the up arrows refer to the parallel change with the feature active, while the current code remains as it is with the feature inactive.
Dependencies
There is a strong dependency with the squad in charge of materialized properties, as well as data aggregation through the database, to carry out the cases contemplated in case 2 within the solutions to be adopted.
Since the same optimization can be applied in many cases to the same problems (optimizing reports, speeding up page loading, eliminating elastic,...), we will be in close communication to unify solutions whenever possible.