Amazon PSP - SFTP File Transfer
Problem Description
As part of the program requirement of the Payment Service Provider program, a Payment Service Provider (a PSP) must exchange specific data sets with Amazon. Said data sets are either shared with Amazon through an API (Phase II) and through SFTP files (Phase I), covered in this document.
In this project, we have implemented a solution for file compartmentalization via SFTP to Amazon, thus completing the first phase of the Amazon PSPP project. Our aim is to communicate with Amazon every hour about the modifications that have occurred in our tables, in terms of identity, payments and transactions of a subset of our customers. We want to provide Amazon with up-to-date information about the activity of each of our customers with virtual bank accounts and their beneficiaries. This project must be carried out as it is one of the requirements to become a Payments Service Provider for Amazon.
DBT, BigQuery, Airflow, and DAG are tools commonly used in data engineering. They are used for this implemented solution.
For a bit of context:
- DBT is for data transformation and modeling, while BigQuery is a scalable data warehouse for storing and analyzing data. Airflow is a workflow orchestration platform, and DAG represents task dependencies in workflows. Together, they form a powerful data engineering stack for efficient data transformation, storage, analysis, and workflow management.
Background
Amazon requires updated information on customer identity and payments, and it is stipulated that this information should be received every hour.
Solution
The proposed solution for the stated problem is to create a process in dbt that updates the tables in the warehouse every hour, and an Airflow DAG (directed acyclic graph) that subsequently reads these tables. In addition to reading the tables, this process in Airflow will be capable of generating files in CSV format that will be sent to Amazon via an SFTP (S3 bucket) provided by them.
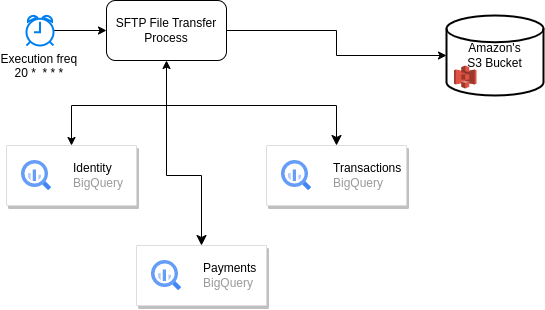
The workflow will involve:
- Raw info transformation. This will be handled by dbt.
- Connecting to BigQuery. To the tables resulting from the process mentioned in step 1.
- Checking if there is any update in the latest hour.
- Transforming BigQuery queries into csv files.
- Storing the files in Google Cloud Storage (for auditability reasons).
- Encrypting and signing files.
- Checking the file contents.
- Uploading the files.
By implementing this solution, Amazon will be up to date with the changes in payments and in identities and files will be available in Google Cloud Storage whenever we need to check them on our side.
Service Ownership
| New Service | Service Name | Service Owner |
|---|---|---|
| No | Generic kafka data loading | DIO Team |
| No | Data warehouse | DIO Team |
| Yes | Amazon SFTP Data Sharing | DIO Team |
Alternatives
We have the following alternative to uploading data to Amazon in an Airflow DAG:
It would consist of having a Cloud Function capable of performing the same functions, which are extracting information from BigQuery (if there are updates), inserting this information into a CSV file, reviewing the contents of the files, and finally encrypting and signing.
The mentioned Cloud Function would be invoked every hour using Cloud Scheduler and Google Pub/Sub. Specifically, every hour Cloud Scheduler will write to a topic to which the Cloud Function is subscribed. Once it is written to the topic, the subscribed Cloud Function will be triggered, starting the entire process.
Pros:
- Google Cloud Functions automatically scale to handle variable workloads.
- We as users only pay for the code's execution time.
- We don't have to worry about infrastructure maintenance.
- Cloud Functions allow for fast code development, testing, and deployment.
Cons:
- Runtime limitations: Cloud Functions have a maximum runtime limit of 9 minutes.
- Limited scalability: although Cloud Functions scale automatically, scalability can be limited compared to Airflow.
We have chosen the option of processing and uploading the data with an Airflow DAG because we have extensive knowledge of Airflow's operation internally, as well as automation and templates to generate a DAG based on a container stored in Cloud Registry.
On the other hand, we do not run the risk of exceeding the maximum runtime of 9 minutes for Cloud Functions. We also have scalability in Airflow, which is less limited than what we would have in Cloud Functions.
Caveats
Some caveats to consider for the proposed solution:
- Data availability: The success of this project depends on the availability of the data being extracted from BigQuery. If the data is not available (due to an issue with the dbt process) no data will be uploaded to Amazon, causing an incident.
- To mitigate the effects that this problem may cause, the team has developed a service that, after each execution, certifies that if there was information in BigQuery, it has been deposited correctly.
- Credentials expiration: It is necessary to keep in mind the expiration date of the credentials, both for encryption (provided by Amazon) and for the signature (generated by us and shared with Amazon).
- Security: It is important to ensure that the solution is designed with security in mind, and that appropriate measures are taken to protect sensitive data. Access to the data should be restricted to authorised users, and appropriate security controls should be put in place to prevent data breaches.
Operation
The proposed solution involves extracting data from our warehouse and subsequently uploading it to an S3 bucket provided by Amazon. Analytics Engineering is responsible for data modelling, the DIO team is responsible for ensuring that this data is sent to Amazon encrypted, signed, and at a frequency of one hour. The Support team is responsible for launching the dbt and Airflow processes according to the steps outlined in the Runbooks. The Service Level Agreement (SLA) is established and all the parties involved are aware of it to ensure smooth operations and efficient issue resolution.
Security Impact
The proposed solution may have potential security impacts on the system, such as:
- The solution involves handling user-provided data, which may introduce security risks if not properly validated and sanitised.
- The solution requires access to sensitive data such as user authentication tokens or keys, which must be handled securely to prevent unauthorised access.
- The solution requires cryptography and signing(as per stated in the Technical Specs), which must be implemented using secure algorithms and key management practices to prevent data breaches.
- Since we got permissions on the S3 buckets provided by Amazon, we need to make sure that only specific users have access to the credentials.
Considering these potential security risks, the solution is designed and implemented with security in mind, and all relevant security measures are put in place to minimise any potential impact on the system:
- There is only one way to access to the credentials needed, said credentials are stored in Google Secret Manager (Google's secure and convenient storage system for API Keys, certificates and sensitive data) and in order to access Secret Manager the user needs to have permissions to view and retrieve credentials. Only a very restricted set of users have permission to do so.
- The credentials mentioned before grant users access to Amazon S3 bucket, SFTP error server, to the signing and encrypting keys and to the source of data as well, meaning that all the risk are mitigated using Google Cloud Secret Manager. Even the container with the service is uploaded in Google Container Registry, only a restricted group of users (DIO Team) has access to this service.
Performance Impact
The addition of this new service does not affect the performance of other services already in production since it only consumes data and provides the client with the data we possess in a format agreed upon by both parties. We read the information contained in our Warehouse, BigQuery, and send that information in the form of files to Amazon.
As the code will be executed every hour, every day of the year, we run the risk of the process's performance being affected. The main reasons that could jeopardise the process's performance are as follows:
- Unexpected Airflow downtime. The process responsible for collecting and uploading information to Amazon would stop running.
- Unexpected increase in the volume of data and, therefore, in the execution time of the process in dbt. If the dbt process takes longer than expected to execute, we run the risk of both processes overlapping.
To address both scenarios, we propose creating a runbook that allows us to execute the code that runs in Airflow from any terminal. In the case of overlapping, we suggest a process that checks past executions after an hour (at time t, check the execution of the window t-2 -> t-1), notifying the relevant teams of a downtime and being within the timeframe established by Amazon for the code to be re-executed following the steps in the runbook.
Data Contracts
In the case of this RFC, it is not clear from the information provided whether there will be any changes to existing data contracts or the creation of new data sources. If this is the case, it will be important to identify existing and new consumers of the data and communicate any upcoming changes, including details of backwards, forwards, or full compatibility. It will also be important to detail the changes to the data contract and ensure that it follows the patterns outlined in the relevant standards and patterns documents.
Data Sources
The moment the process gets executed the information already resides in our warehouse, but nonetheless, the source of the data or what feeds the warehouse is as follows:
- Systems:
- Salesforce
- FenX
- Data sources:
- Salesforce. The report is built on top of the following Salesforce objects:
- Account
- AccountContact
- Contact
- IdDoc
- Case -> Out of Scope. Only needed for lastKYCDate which is extended.
- Director -> Out of Scope. Only needed for email and phone which is extended.
- Kafka. The report is built on top of the following Kafka topics:
- fenx_Kafka_Synchronized.entity. We rely on FenX to obtain the Id Docs related to new clients onboarded on FenX, as this object is not synced back to Salesforce.
- Salesforce. The report is built on top of the following Salesforce objects:
For more info check the following document.
Deployment
The application deployment has been carried out by the DIO team. First, the service that models the data and results in BigQuery tables has been deployed on dbt Cloud. At the same time, the code is uploaded to Google Container Registry. Using the Airflow templates previously mentioned in this RFC, an Airflow DAG is configured in the project project_akme that points to the Container Registry container where the code resides.
Once the process is up and running, runbooks with the steps to be followed by the Support team in case of failure in each of the parts (dbt and Airflow) are created. For this last part, coordination of all teams (Data, DIO, and Support) is necessary.
Project repo.