Mass payments: async API
This document reflects the proposal of including support for background jobs in the API layer, so the offered experience can include richer flows.
Problem Description
Currently, API is a transformation layer exposing synchronous HTTP endpoints only. We want the API user experience to include some async operations. The user could trigger them, and then check the status and results later.
For example, and to define the scope of the document: some users need the mass payment experience to be executed async.
Background
Business logic coded in the backend was never intended to be exposed a public API. This is because backend does not need to be tied with the specific flows and operations we want to expose to the public.
In our example: BOS has mass-payment endpoints, currently synchronous, but an incoming rearchitecture will probably embrace asynchronicity. None of the two options should be a limitation factor for the API. API must be able to expose user flows regardless the backend implementation.
Solution
This document explores an approach for the mass payments creation that integrates the workflow orchestration in the API. That way, instead of being constrained by the backend code, API layer is free to own it and evolve it in the future.
The solution proposed is to extract the logic, from the HTTP request-response cycle, to the background. To do that, we can use existing libraries that allows us to keep the code where it lives now, e.g. rq. The same docker image can be started with a different entrypoint, in a similar way that celery uses in django.

This background job needs a persistence layer, luckily API already got a redis instance. The job state in redis will host the minimum information: a UUID, the user input, the job status. The rest of the information is to be stored in the backend, without data duplication.
The app-webapp HTTP server that spawns the creation job can generate a UUID for it: so the user can receive it, and query the job information later.
The rest of useful information will still be retrieved from BOS, which will continue to be the source of thruth.
BOS needs a small modification to support this: the mass-payment object needs a new field MP-UUID.
This field is to be optionally expressed in the creation, and later to be used as the filter.
Given the second part of the creation can need a user confirmation, then the proposal is to split the flow into two jobs.
The confirmation job can be scheduled directly by the first one if accept_immediately is set.
Otherwise, the job is to be spawn only after the user makes a HTTP call to the right endpoint.

The jobs can use the current code.
Said that, it is probable that the final user journey includes some necessity to report the specific job status.
In that case, the status can be stored in the job state (redis) with the values shown in the activity diagrams.
Also, the flag with_errors can be updated to decorate some of the statuses. E.g., "processed" and "processed with errors".


We plan to also keep the synchronous functionality for now.
Alternatives
The other alternative considered is described in the parent document.
Caveats
This solution is intended to allow for background jobs that can unload the HTTP main API flow and allow for fast async endpoints. It is not designed to cover business flows, or to keep historical information about the jobs executed.
Operation
Deployment
The obvious choice here would be to add a new container to the ECS task. However, we have several problems:
- Our webapp terraform module does not allow to easily do that
- Modifying the webapp module is not a good idea because we are moving to k8s
- It is unclear if/how this module will evolve to support k8s, or just be superseeded by helm and raw pods
Other parts of the architecture are solving this just creating several tasks to host the different processes. This alternative also has some problems:
- The docker image need to be the same, but different services deployment can get the workers outdated
- The network connectivity must be double checked, to review if for the new task the same rules still apply
- Monitoring and alerts need to be extended to cover the new task
- The same configuration need to be passed to the new task, generating a duplication and with it: a potential divergence
Said that, the proposal is to start a process manager inside the container that split the control to the two entrypoints.
This is a trade-off that allows for a running solution, that can work in local, devel, sandbox and production.
When the k8s deployment mechanism is instrumented, these two processes will return to be two containers with the same image and different entrypoints.
A process manager like supervisord is reliable enough (and cited in docker documentation).
Monitoring
The proposed library stores state in redis and allows for the CLI to retrieve stats, and a web user interface.
Console interface:
$ rq info
high |██████████████████████████ 20
low |██████████████ 12
default |█████████ 8
3 queues, 45 jobs total
Bricktop.19233 idle: low
Bricktop.19232 idle: high, default, low
Bricktop.18349 idle: default
3 workers, 3 queues
Web GUI:
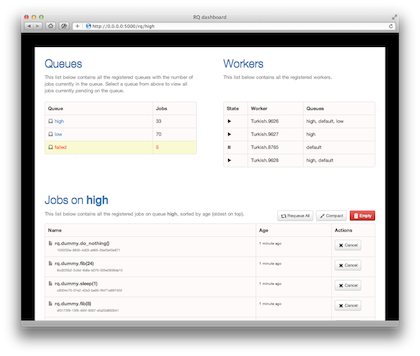
If the solution selected is to create a new task, we need to create monitoring rules and new alerts for it. Otherwise, including a new process inside the same container, we only need to check the memory limit of the task.
Security Impact
The scenario presented includes reusing the same code built into the same docker image, with the same network configuration.
No security impact forecasted.
Performance Impact
The ability to run background jobs has no impact on the performance.
Developer Impact
The library proposed is new to the team and we will need some time to grasp it. However, the mechanism is similar to the one used in the well-known celery, and totally testable. The key of this solution is the ability to run some parts of the code as background jobs without modifying or extracting the code. That means the developer experience will be confortable, no need for external tools or new languages.
Data Consumer Impact
None.
Deployment
Already discussed in the Operation section.
Dependencies
The presented idea can be executed without dependencies on other teams.
References
None.