ICE Trade Updates
Intercontinental Exchange's system (ICE) has been used to manage Dynamic Forwards and Options since 2022. Ebury now needs to extract transactional information from ICE to drive internal Ebury processes.
Reference Documents
| Reference | Document Location |
|---|---|
| DFO0001 | DFO Services blueprint |
| PRD ICE Polling requests to retrieve updates | |
| ICE Vendor Technical Documentation | |
| Tech analysis on ICE updates polling | |
| EPIC01 | RFC template |
Problem Description
Dynamic Forwards and Options trade information is stored primarily in ICE, although some information in ICE originates from other services, e.g. Salesforce and BOS.
Updates made to trades in ICE needs to be made available for Ebury's internal processes, e.g. to:
- Handle transaction receipts
- Feed the Exposure Dashboard
- Forward information to Quantum
- etc.
Updates do not need to be immediate but should typically be available in a reasonable period of time, e.g. within 15 minutes.
ICE provides an authenticated HTTP JSON/XML API. Ebury processes should not need to talk directly to ICE, and should be shielded from ICE's API and data complexity as far as possible.
A new component in the DFO Trade Engine service is needed to integrate with ICE and publish updates to ICE trades in a meaningful form for any other Ebury processes to use.
Background
DFO Trade Engine
This document covers the high-level design of a new component within the DFO Trade Engine and builds on the Dynamic Forwards & Options Services, specifically:
- ICE Gateway to abstract access to the ICE API
- Kafka to publish events related to trades for other processes to consume
- Persistence to track state
ICE
General Usage
ICE is typically used to set up a trade package - a set of trade legs to achieve the final goal. The client's initial package is mostly automated, and ICE provides validation to ensure basic consistency. However, a trade package is then manually modified, e.g. to assign liquidity providers, fix mistakes, etc. This means copy-paste-changing trade legs, amending amounts, deleting duplicates, etc.
ICE also holds indirect data referenced by trades, e.g. client names and their Ebury internal identifier, portfolios, etc., which is also manually managed.
Due to many ICE operations being largely manual, it's assumed there will be some inconsistencies in ICE data, e.g.:
- Portfolio names may not be in the expected format
- A trade leg may have no counterparty.
- A client counterparty may not have an internal ID (manually copied from BOS)
- Trade codes (Ebury's trade package identifier) may not be assigned or may not be in the expected format
- etc.
API
Changes to ICE trade legs over time are accessible using the ICE API, with some caveats:
- Only the latest state of a trade is available
- No information on deleted trades is available (see Caveats)
The ICE API includes IDs that are only useful in the context of ICE itself. These IDs would be dangerous if passed on to other Ebury processes so should be mapped to more meaningful values.
Publishing invalid trade information would be confusing and may even cause errors in other processes. As a result, validation and mapping from ICE to EBury is necessary.
Solution
The basic solution will be an ETL engine to extract trades from ICE, validate and map data for Ebury's internal use, and publish messages to Kafka for other business processes to consume.
Principles, common to all phases, are:
- ICE updates must not be missed (but see Caveats)
- Updates must be published as messages to Kafka for any future processes to consume
- Updates must be published in relevant strict time order
- Kafka messages should not be duplicated under normal circumstances
- Exactly-once delivery cannot be guaranteed, so updates must include an idempotency key
Kafka Topics and Messages
ICE trades legs are part of a trade package for a client, but each trade leg is an independent entity. Consumers must see updates to a specific trade leg in the correct order, but should be able to scale horizontally to increase overall throughput.
The latest full state of a trade leg will be published as a Kafka message. A trade leg's Ebury identifier, e.g. "EBFX12345678001", will be used as the Kafka message key. Topics can be compacted with no loss of information.
A trade leg's ID / message key will be used to consistently derive the topic partition ensuring consumers receive message in the same order. A sensible number of partitions can be chosen to allow consumers to scale.
Ebury processes that will consume the updates do not yet exist and requirements are unknown. Topics must store messages indefinitely.
Messages will be Domain Events, either in ICE-specific format (Phase I) or an engine-agnostic format (Phase II). The structure of these Domain Events will differ but must include core fields to allow consumers to handle messages according to teir requirements:
- ID - the trade leg's unique Ebury identifier, e.g. "EBFX12345678001".
- Modified timestamp - time of last update, for use as an idempotency key (not ideal, but the best available)
Phase I - Extract Trades from ICE
The initial phase will focus on the core ETL problem of extracting trade updates from ICE. Published updates will be similar to the original ICE data, but with ICE identifiers mapped to Ebury identifiers, etc. This will allow other processes to consume ICE trade updates, as well as drive Phase II.
This phase will also be used to validate and improve data consistency in ICE if necessary.
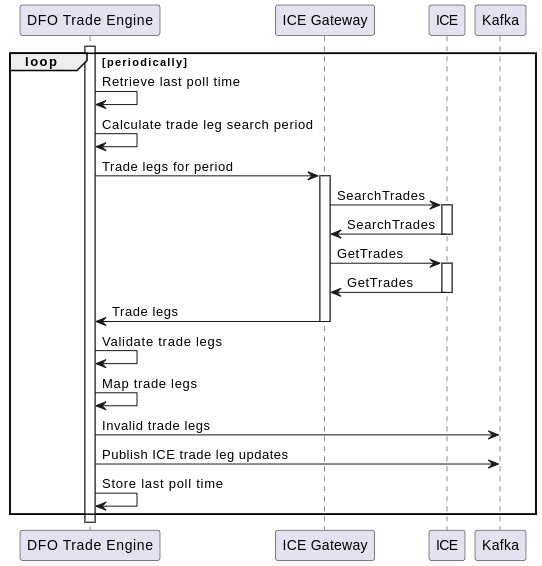
- Poll ICE for trade updates
Careful use of ICE APIs, selecting the poll time range, etc., should mean duplicates are avoided unless processes crash unexpectedly.
The new component in the DFO Trade Engine will maintain minimal state about previous poll times, and use that to calculate a time period for this poll. The time period will be chosen to help avoid the chance of duplication.
The ICE Gateway will handle the interaction with ICE which involves two API calls - SearchTrades followed by GetTrades.
The result is a list of trade legs that were updated in the poll's time period.
Note: Only one polling process should be run concurrently to ensure there are no race conditions that may publish trade leg updates out of order.
- Validate trade legs
Each trade leg will be validated (as far as possible) for correctness. Validation errors will mark the trade leg update as failed.
- Map trade legs
Any ICE-specific identifiers, e.g. client counterparty names, will be mapped to the internal Ebury equivalents.
Mapping can also be used to simplify the data, make fields more consistent, fix up timestamps to include a timezone, etc.
- Route validation failures to support
Trade legs that fail validation will be routed to support, probably via a Kafka topic (shown here) and an additional workload to send emails.
Routing validation failures will drop updates from the ordered log. The failure may even be transient, e.g. someone was in the middle of a change, and will have been corrected by the time of the next poll. Fortunately, only the latest state of a trade leg matters. The validation issue can be ignored if already fixed, or the trade leg can be amended as necessary. An amended trade leg will be seen by a future poll and the latest valid state will be published.
There is no plan for additional state at this time but could be introduced later to improve failure messages, e.g. if many failures are transient and cause excessive noise.
- Publish validation successes as "ICE trade update" events.
Valid trade legs will be published as a well-defined but flexible Domain Event to a "ICE trade updates" Kafka topic for other processes to consume.
Phase II - Engine-Agnostic Domain Events
Ebury processes should typically not need to know a trade came from a specific engine, e.g. ICE, BOS, etc. Ideally, trade updates would describe changes in a way that abstracts the source of data, allowing processes to handle messages in the same way regardless of the original source.
At this point in time, it is not clear if this is required but. If useful, it can be driven by messages in the "ICE trade updates" Kafka topic. A new well-defined Domain Event and new topic would be needed.
Consumers switching from "ICE trade updates" to the new events will need a migration plan. If no "ICE trade updates" consumers are left, that topic's retention policy could be relaxed to reduce the amount of storage needed.
Service Ownership
| New Service | Service Name | Service Owner |
|---|---|---|
| No | DFO Trade Engine Service | TEG Team |
| No | ICE Gateway | TEG Team |
Alternatives
No known alternatives. The approach is (loosely) based on advice from ICE support.
Caveats
- ICE data to be published almost "raw" for now.
Initially, any consumers will need to understand the structure of ICE messages.
- The ICE API does not provide updates on deleted trades legs.
At this time, it seems there is no way to tell when a trade leg is deleted in ICE. If a "ICE trade update" message has already been published, processes will never know it's since been deleted.
This is likely to cause inconsistency and inaccuracies.
Operation
The new component is for internal use only and will be deployed as part of the existing DFO Trade Engine, already running in Kubernetes.
Polling scheduling will be managed by the new component, e.g. a Kubernetes CronJob, persistent process, etc., as necessary.
Security Impact
Secrets
Access to existing database credentials will be required. The credentials are already managed using Vault.
Access to Kafka credentials will be required. The credentials are already managed in AWS and available to Kubernetes workloads as an External Secret.
SMTP or similar credentials may be needed for failure notifications and would be managed using Vault.
Secrets will never be exposed outside the workloads' containers.
Performance Impact
Poll time is expected to be around 15 minutes. This should provide a balance between CPU load (how often and hard it runs) and RAM (how many updates are in flight during each update). The poll time can be updated as necessary, and it may also be possible to split updates into smaller batches internally.
If backfilling from ICE is necessary, there may be a flurry of activity at first before it catches up with present time and settles down.
Kafka will potentially persist at least one copy of every trade leg in ICE.
Developer Impact
No known issues.
Data Contracts
ICE Trade Update Domain Event
The domain event will be defined more fully during development, but is expected to look something like:
id: "EBFX12345678001"
creationTime: "2023-07-13T13:04:59Z"
lastUpdateTime: "2023-07-31T14:50:53Z"
ebury:
client:
id: "..."
tradeCode: "EBFX12345678"
ice:
tradeLegId: 57156229002
tradeId: 57156229
tradeType: "Vanilla"
... simplified original message ...
Core attributes are needed for general handling of messages and consumer idempotent behaviour (see above).
ebury contains Ebury-specific information implied or mapped from the content of the ICE trade update.
ice contains the original data from the ICE trade update. This is likely to be simplified and made more consistent (see above).
Data Sources
-
Input data sources - ICE
-
Transformation requirements - consistent IDs and idempotency keys, mapping ICE IDs to Ebury internal IDs.
-
Output data - ICE-Specific Domain Events to a Kafka topic
Deployment
Other that the Phase I and II split, there are not expected to be any unusual deployment issues.
Based on RFC Template Version 1.1