Development environment in Kubernetes
This document describes a high level proposal for having a development environment running on a Kubernetes cluster, preferably a remote cluster, with the same capabilities as the current ED2K environment based on docker-compose.
Problem Description
As the roadmap for moving Ebury transactional platform into Kubernetes begins to be a reality, there will be a need for developers to run and test their code in environments closer to production.
As a developer, having a local environment is desirable for a faster feedback loop and in order to have more fine-grained control for reproducing complex scenarios. Also, not relying on VPN connection is always interesting.
For the company, maintaining development environments in the cloud for each single developer would mean significant costs, as we could be talking about a cluster with up to 100 nodes, that could be up to 10.000 $ per month (very rough estimate). However, a full remote solution or a hybrid solution can be more efficient taking into account that the size of the full platform could not fit into a laptop, and the costs of laptops with humongous amounts of RAM is also significant.
Background
ED2K
The current development environment is the so-called ED2K (Ebury Dockerised Development Environment), a set of docker-compose definitions wrapped in Makefiles, using Nginx proxy that listens to Docker events as a poor man's service discovery.
Resources shared between projects (Kafka, Localstack, etc.) are defined in a centralised core, in ED2K repository together with Nginx proxy.
Each project can define their own set of resources (database, cache, sqs/sns definition) and applications, which then registers automatically in Nginx proxy for interacting with other services and projects.
Beyond the ability to spin up Ebury's platform locally, there are several essential capabilities that the ED2K provides:
- Fast inner loop, so changes are (generally) propagated immediately from the IDE to the running environment.
- Ability to start only the significant parts of the platform that is needed for a given development.
- Tools for restoring databases, including obfuscated copies of production databases.
Ebury platform makes use of a number of AWS resources:
- RDS
- MSK
- ElastiCache
- ElasticSearch
- DocumentDB
- DynamoDB
- SQS
- SNS
- S3
In the ED2K local environment, we rely on Localstack for DynamoDB, SQS, SNS and S3. For the RDS, ElastiCache, ElasticSearch, DocumentDB and MSK, we run specific containers with PostgreSQL, Redis, ElasticSearch, MongoDB or Kafka.
With the growing number of services in the platform, starting the environment locally for integration tests and keeping it up to date is becoming complex and resource demanding. At the time of writing, it is already difficult to fit the environment in a regular laptop.
We follow a multirepo approach for source code control, with every service having their own lifecycle within their repository. There is some proof of concept for monorepo in some parts of the platform (specifically, the API Events).
EBOX
Based on ED2K and running on EC2 instances, it is possible to create preview environments in the cloud (a.k.a Ebury Boxes (EBOX)), with preloaded copies of obfuscated versions of production databases. However, adding new services to be supported in EBOX is somehow complex and tedious, and not all projects are supported. The environments are created on demand with Jenkins jobs, and destroyed automatically on a daily basis if not told otherwise.
Those environments are also the basis for several persistent environments in production, like Demo and Sandbox.
Ecosystem
Regarding the Ebury platform ecosystem, there is a recurring pub/sub pattern in applications for Ebury 1.0, where several containers serve as producers and consumers, but using the same image. Pub/sub is implemented in different ways, it can be Celery, plain Redis, or SQS. The consequence is that a change in code has to be propagated to multiple running containers with the same image but different entrypoint.
Ebury 2.0 will rely heavily on an event bus with Kafka.
Solution
Create and maintain one (or several) Kubernetes clusters in the cloud (the Devel Kubernetes Platform), and provide a set of tools for creating isolated environments spinning up all or part of the Ebury transactional platform. Environments will be isolated by running in different namespaces.
Environments
Take into account that we are talking about a Developers' cluster, not an integration cluster where artifacts intended for production will be tested in an automated way, or a cluster where infrastructure changes are tested. The sole purpose of this cluster will be to create isolated environments where Ebury platform can be spun up for development.
There will be multiple environments. We will avoid calling them development as there will be multiple stages in SDLC. The following definitions apply:
- Local: The developers' laptop.
It is expected from services to be able to start locally with mocks for any external dependency. Unit tests, linters, etc. are also expected to be executed locally, providing simple make targets for CI or occasional developer to execute them as well without additional configuration. The way to do so is responsibility for each service, and out of scope for this document.
There will be no official support for running several services in integration locally, neither
with docker-compose nor with a local emulation of a Kubernetes cluster.
Testing the integration between services beyond mocks (either manually or automatically) will be done in a ED8K environment.
- ED8K: A Kubernetes cluster (named Dev) with multiple environments (named ED8K) able to start a fully functional platform in isolation.
The purpose of the environments is to test a development version service in integration with the rest of the platform, in a way it is possible to debug and to quickly iterate over different development versions, even before anything is uploaded to source code repository.
These are the environments being covered in this document.
- Staging: A environment where artifacts built in the CI system are deployed automatically.
The purpose of this environment is for testing artifacts before they land on production. Only versions intended for production should be deployed here.
There may be multiple staging environments where artifacts progress along a pipeline towards production, having different quality gates on each staging environment, but it is out of scope for this document.
Multi-tenancy
Each environment in the cluster will be isolated in a Kubernetes namespace. The namespaces will be self served with the help of ed8kctl (https://github.com/Ebury/ed8kctl). It provides helpers for workspaces management and for starting different sets of applications.
Some templates will be deployed at namespace creation, containing core parts of the platform, while other templates will be in charge of starting optional parts, usually other services. Templates are defined by cluster administrators or services' owners and namespaces are created by users.
Development engine
The intention is that a change in code goes from the IDE to the cluster in seconds, not minutes, so we will avoid following the build & push & deploy procedure that we would follow in Production or Staging. It should be possible to update a running service's code from the laptop without committing anything to the code repository. There are a bunch of modern tools for this purpose, supporting file sync between the local directory and the filesystem inside the running container in the Pod.
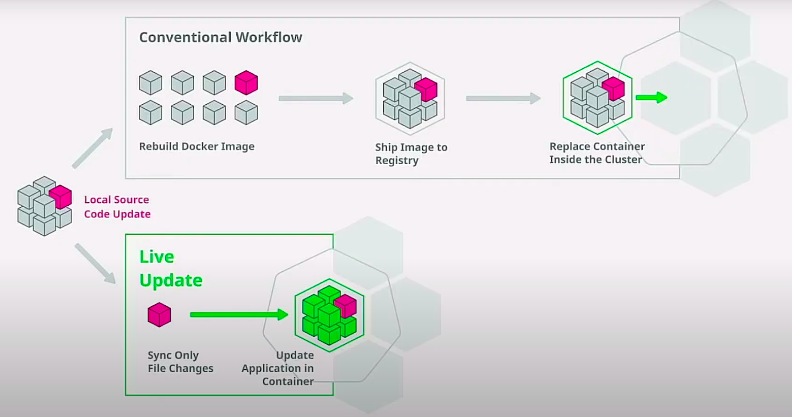
For live update capabilities, we will use Tilt.
This tool was compared with some others, like Garden, Draft, Skaffold, DevSpace and Okteto, etc.; the offer is overwhelming.
The decision regarding the tool of choice was based on these desired capabilities:
- Being a tool with active maintenance. This means that bugs are fixed, and code is released more often.
- Ability to run logic beyond just synchronizing, based on which files change. For compiled languages, for instance, a code rebuild may be needed. Webserver restart is also a possibility, as well as library installation (or full container rebuild) if dependencies change. It can be argued that a developer should be aware of when those changes are needed if they are introducing a new library, but it is quite common problem that, when a developer update their branch with changes from upstream, dependencies are updated, and it can take a while until it is noticed that new dependencies need to be installed.
- Use K8s syntax as much as possible. Resources should be defined with K8s' yaml files and not with any intermediate syntax that then produces K8s' yaml files.
- Ability to run remote debugging tools.
- In any case, the tool will be in charge of starting a single application in a repository. The user will both create its workspace and start several services with versions from Production with ed8kctl, and then will replace one or more of the services with the development engine. Although not desirable, different projects could use different development engines.
DXP team will only officially offer support for the tool.
Project resources definition
The projects will define their resources as Helm templates in their repository, so the aforementioned tool must support creating resources from Helm templates. Different configurations for the template will allow different resources size, different environment variables and different base dataset (obfuscated, development), etc.
The way Helm charts are published and deployed is coupled to the way services and updates will be deployed in Production. It will be discussed and published in a different document that will cover the deployment process.
Telepresence
Sometimes, developing or debugging directly in the cluster may not be feasible. For those cases, support for running https://www.telepresence.io/ will be provided. Telepresence allows running a container or process locally, handling the proxy networking to make it look like a Pod in the cluster namespace.
AWS resources
AWS resources that cannot be shared between environments, like DynamoDB, SQS, SNS or S3, will be created as actual AWS infrastructure through Kubernetes operators, with each service defining their own needs, and using namespace as prefix to resources to avoid collisions in naming.
There will be a single MSK cluster, with topics being created also through K8s operators in different node groups as is already being proposed for production infrastructure.
It is still pending to determine the feasibility (or even the suitability) of sharing RDS, ElastiCache, ElasticSearch or DocumentDB instances, defining the database as a resource. Serverless resources may be also possible, like Aurora serverless.
In any case, any resource that in a production environment is created in AWS, will be expressed by the service as a CRD, and then created in a specific implementation through operators, either as an actual AWS service, as a service in the cluster, or as configuration for an existing infrastructure.
By providing abstractions to resources as CRDs, the actual implementation can be changed and deployed to all the environment without modifying the service definition.
AWS Service operator, Crossplane (https://crossplane.io/) and Terraform operator are the options for defining AWS resources as K8s resources. In house built operators for simple tasks (https://github.com/operator-framework/operator-sdk), would be also a feasible option.
Preview environments
Together with environments directly created by developers from CLI, it will be possible to create preview environments, directly from actions in an open Pull Request, this can be achieved with Bitbucket Pipelines or GitHub actions.
The previews will be replicas of the integration environment with the modified version for the project in the Pull Request, although several flavors with more or less data and more or less bits of the platform should be provided.
Once created, it will be possible for developers to deploy their local changes in those preview environments, either for the project being previewed but also for other projects.
Building images
It will be possible to build images remotely in the k8s cluster, making full usage of remote cache, faster internet connection and removing the need for having VPN if the build uses private libraries. Kaniko is a feasible option for this feature.
Cleanup
Preview environments will be destroyed manually by the user, or automatically on a daily basis unless told otherwise. This will include destruction of the persistence in the database as well.
The running bits of development environments will be destroyed on a daily basis, but its infrastructure (mainly the databases) will be kept stopped. Regularly, environments whose databases are not receiving connections for a period of time will be destroyed.
It will be possible for the user to override the cleanup behavior for a particular environment.
Alternatives
Other multi-tenancy tools
Kiosk: Deprecated. The project has been discontinued and no longer has support for new versions of Kubernetes since 1.22.
There are other tools for multi-tenancy. K8Spin and Capsule seem less mature than Kiosk. Plain K8s multi-tenancy support could also be possible, but it would not provide support for templates.
Loft (https://loft.sh/) is the enterprise version of Kiosk (more than enterprise version, it is a product built on top of **Kiosk by their creators and maintainers), providing easier administration for namespaces, including a sleep mode, a UI for starting and stopping workspaces, authentication, and virtual clusters. However, the pricing starting at 20$ / user/month is quite high.
VCluster deploys a whole functional Kubernetes API inside a namespace, but the process of determining which objects to synchronize from the VCluster to the Host and vice versa is highly complex. This complexity arises from various factors, including the need to consider the specific requirements and dependencies of each object and the potential conflicts that may arise during synchronization.
Furthermore, creating synchronized objects in the Host namespace requires additional permissions, adding another layer of complexity to the process. These permissions must be carefully managed to ensure proper access control and security.
Starting environment in local cluster
With the growing number of projects and services, which are likely to increase in the near future as we are building a distributed platform, starting the platform locally is more a burden than a benefit.
Enterprise versions for development engines
Most of the aforementioned tools (Tilt, Okteto, ...) provide enterprise versions for managing environments or running on managed clusters. No study for those capabilities has been performed yet, but it would bring capabilities mainly for environments administration
Inlets
Similar to ngrok, it can create a tunnel from a computer behind NAT/firewall/private networks to one on another network such as the internet.
It could be an alternative to Telepresence. It can be automated with an operator: https://blog.alexellis.io/ingress-for-your-local-kubernetes-cluster/
It is free for HTTP traffic, with enterprise license allowing plain TCP.
Connect development to a shared integration environment
A single environment, or one environment per team, could be configured, then allowing the different members to coordinate its operation. However, it would be difficult to control the different developers not interfering with other environments if they share the database and the event bus.
Ambassador Cloud
Built on top of Telepresence, it allows to replace the remote pod with a process running locally, but just for the traffic coming from requests originated in a specific preview URL. It could be a solution for sharing an environment between multiple developers.
Free for unlimited developers... but up to 5 services and 5 requests per second. Pricing model beyond that is a bit obscure.
Provide ED2K <-> K8s compatibility
With ED2K running locally, and a K8s cluster running also locally, it could be possible to use Ingress controller and ED2K Nginx proxy for routing requests back and forth. That could be quite straight forward for HTTP traffic. For TCP traffic, we could use a set of Traefik or Nginx acting as TCP proxies together with a set of hardcoded ports for shared TCP services (mainly Kafka and some Redis databases).
However, although we have a running proof of concept for services in ED2K communicating with services in a local K8s cluster and the other way around, it has too many moving pieces, and the effort to develop and maintain those gateways is considered to be too much for an interim solution. All the focus will be put on having a development environment for services already moved into the new setup.
Caveats
Kiosk was a fairly new OSS tool, not fully adopted by the community, and backed by a start-up that did not progress, so the risk that it would cease to be continued has been fulfilled, and therefore we have had to stop using it. In fact, there is no commonly adopted tool for this purpose, with most of the industry has relied on custom in-house built solutions for self served namespaces.
The proposal do not support having nested or hierarchical namespaces, but it is quite likely that our production environment will have different namespaces for different domains. As we are establishing namespace as the isolation tool for different environments, it will not be possible to replicate exactly the same topology as in production in these environments, and further tests on integration or staging environment would be needed for those use cases.
By creating actual AWS infrastructure (RDSs, SNSs and SQSs, etc.) together with the environment, we will be restricting the creation of environment to EKS, renouncing GCE or local clusters. This can be mitigated in the future by creating and maintaining versions of operators that create resources within the cluster instead of actual AWS resources.
Relying on a single cluster for developers will mean that any outage or degradation in that cluster, or bug in the tooling, may lead to a high severity incident.
The creation time for some AWS resources is not exactly fast. Moreover, the cross-region resources like S3 can have quite a long removal time, not allowing to create a bucket with the same name even after one hour.
Offline development for services in integration with other parts of the platform will not be possible, or at least unsupported.
Operation
There will be a shared responsibility in the creation and maintenance of K8s projects and resources:
- Maintenance for K8s definition of resources shared between projects will be responsibility of the DXP team.
- Maintenance for K8s definition of projects will be responsibility of the development teams following provided standards.
Environments (namespaces) will be automatically turned down after office hours unless told otherwise, and the cluster will scale in or out based on the present workload.
Costs will be managed as efficiently as possible, maybe reserving a base computing cost, relying on demand or spot instances for scaling the cluster. This is out of scope for this document.
The cluster or clusters will be built following standards and common tools that are going to be used in all the clusters alongside Ebury. That standards are currently being defined by the Platform Core team (PC). Monitoring for the cluster will be part of those provided tools.
Security Impact
All users in the cluster are considered trusted actors, so soft multi-tenancy offered is enough logical separation for the different environments.
There will be no customer data in the cluster. Datasets provided will be either a full copy of the obfuscated databases, or a truncated version. Any need for testing with production data will be performed in a different environment.
Although API Authentication and Authorization will we controlled with RBAC and IAM, an additional
layer of security for not exposing kube-apiserver to the internet is considered necessary.
In order to provide a good development experience, this additional layer should not be the VPN, as it is already causing a degraded development experience, which would be accentuated if the development platform is fully remote. Further analysis with alternatives to VPN will be done in a different document. However, firsts iterations in the proposed environment will be restricted to VPN.
Performance Impact
N/A
Developer Impact
As this document proposes a whole new paradigm for development, the impact in developers will be huge. Training, show & tells and frequent feedback gathering will be needed.
No backport or intercommunication will be done to the current ED2K environment, meaning that some teams will be moving between different environments depending on the scope of the task.
Data Consumer Impact
N/A
Deployment
The developers cluster will be an EKS cluster provisioned in Ebury AWS Development account, in
its own VPC (CI).
DXP Team will be in charge of providing support for running FXSuite and BOS projects in
the cluster, together with the shared infrastructure like Kafka, as MVP.
Then, the DXP team will provide tutorials and templates for engaging the different teams to bring their projects to the cluster. In the first phases, no operators or CRDs will be defined, and all resources will be created inside the cluster or in localstack running as containers in the environment namespace. Build will be done locally also in the first phases.
The initial MVP will have support for loading databases with SQL dumps. Loading the obfuscated database from snapshots on environment creation will be possible once the CRDs for databases are available.
Dependencies
N/A
References
RBAC and IAM
- https://aws.amazon.com/blogs/containers/kubernetes-rbac-and-iam-integration-in-amazon-eks-using-a-java-based-kubernetes-operator/
Operators
- https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
- https://sdk.operatorframework.io/docs/building-operators/ansible/tutorial/
- https://loft.sh/blog/kubernetes-crds-huge-pain-in-multi-tenant-clusters/
- https://aws.amazon.com/blogs/containers/aws-controllers-for-kubernetes-ack/
- https://crossplane.io/
- https://github.com/hashicorp/terraform-k8s
Multi-tenancy
- https://cloud.google.com/kubernetes-engine/docs/concepts/multitenancy-overview
- https://medium.com/swlh/starting-an-internal-kubernetes-offering-a1cd3bed2e0
- https://loft.sh/blog/building-an-internal-kubernetes-platform#what-is-an-internal-kubernetes-platform
- https://aws.amazon.com/blogs/opensource/aws-service-operator-kubernetes-available/
- https://github.com/loft-sh/kiosk
- https://k8spin.cloud/
- https://github.com/clastix/capsule
- https://github.com/loft-sh/vcluster
Development engines
- https://loft.sh/blog/kubernetes-development-environments-comparison/
- https://codefresh.io/howtos/local-k8s-draft-skaffold-garden/
- https://tilt.dev/
- https://skaffold.dev/
- https://draft.sh/
- https://devspace.sh/
- https://garden.io/
- https://github.com/okteto/okteto
- https://www.telepresence.io/
- https://blimpup.io/