FenX Data Extraction (Phase 2)
The data mastered in FenX needs to be consumed by key processes at Ebury. This document covers the mechanisms we'll use going forward to extract Journeys information after extraction of Entities information was covered in Phase 1
Reference Documents
| Reference | Document Location |
|---|---|
| FXDE0001 | Ebury-FenX MI Options |
| FXDE0002 | Salesforce API integration |
| FXDE0003 | FenX Events Registry |
| FXDE0004 | Data Reg. Reporting requirements |
| FXDE0005 | Kong HMAC Authentication |
| FXDE0006 | Fenx Notifications Overview |
Problem Description
Problem was exposed in the previous RFC. Since we cannot use the same approach we had for entities to capture the journeys' information we need to receive audit trail data from FenX events to be able to capture all onboarding modifications into the s3 data lake, where data analytics team will be able to build needed metrics, such as onboarding by country, type or user, granular reports of the different steps, reassessment checks.
Background
FenX provides a number of different events as result of user activity on the platform. For reporting onboarding metrics our data feeds needs to be aware the modifications produced by activity on "FenX Journeys".
When any action happens over any of these Journeys, an event will be triggered from FenX containing a reference to the
endpoint where the full detail of the journey will be described. The event itself only contains metadata of the action
(like event type, relative url, timestamp or other identifiers). The endpoint of a journey detail will return the latest
status of the journey, with all its historic tasks acting as an audit trail, where modifications are contained as a
snapshot including timestamps and status of every action/task. We will be polling this history building the
modifications into Big Query, that using the timestamps of every action will be able to work the audit by processing
journeys events in any order.
See sample of a journey full detail here.
Solution
The solution proposed here, as already said, was already presented in the first stage of the project, where it was decided to go with the tactical solution for the different reasons commented in the RFC.
Now, the absence of an endpoint where retrieving audit trail modifications in a period, with the experience acquired in the first stage with FenX API and Kafka communication, and for moving forward the architecture to the one desired, we propose the following solution, going one step forward to the strategical solution defined in the init of the project.
Overview of requirements
- Service need to receive a webhook where events in Journeys will be notified
- The endpoint must comply with security requirements
- Service will be running as a service with high availability
- Service will write into Kafka the information of webhooks received
- Full detail of Journey will be extracted from the separate API endpoints and moved to Kafka into another topic
- Kafka-connect will write journey detail into data lake
- Service will expose metrics for Prometheus supervision
- Service will generate logs that can be queried in Kibana
Detail of solution
Phase 1 of the project implemented FenXtractor service, a cron job polling hourly changes over entities with the following architecture.
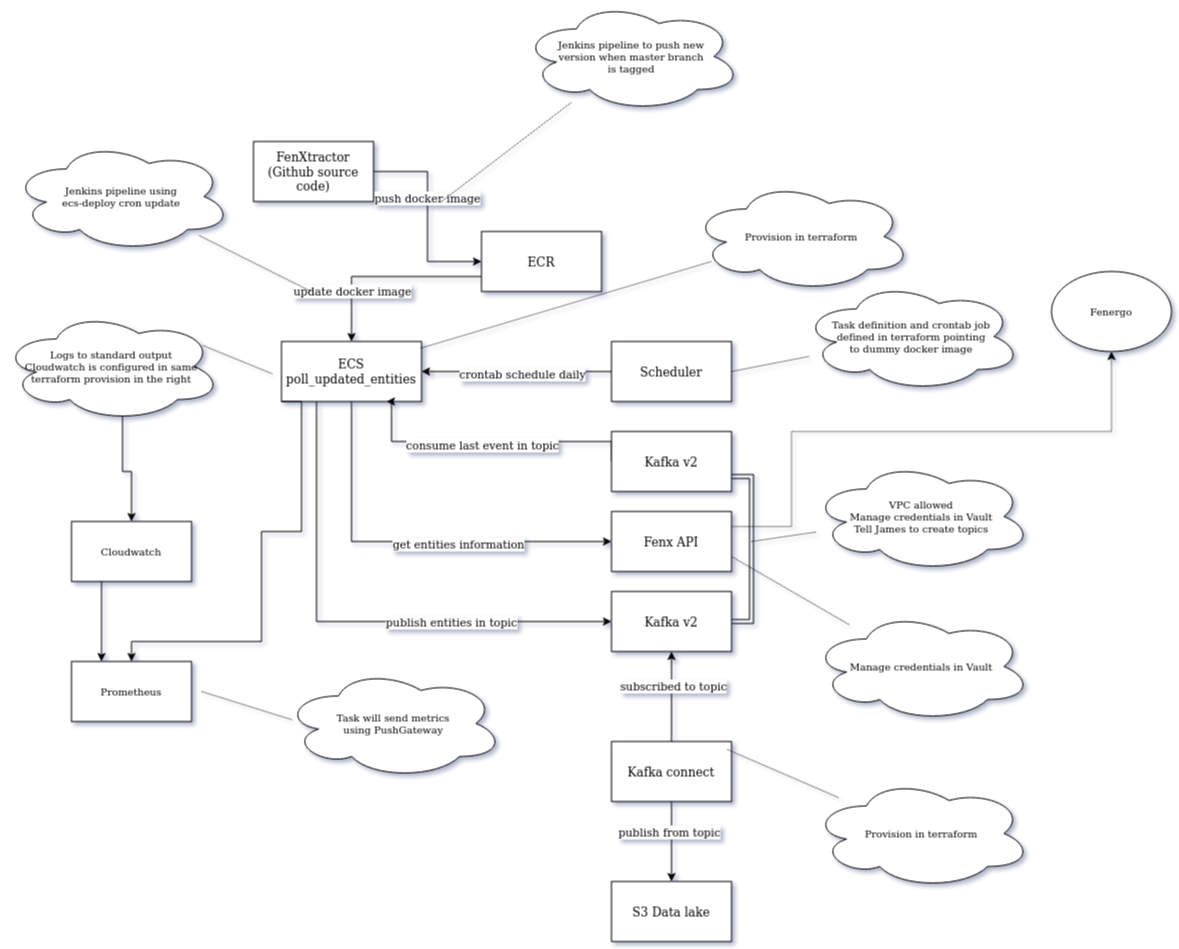
In phase 2 we will keep the polling workflow on a separate job onto FenXtractor service, and additionally we will build a new service with a webhook listener writing into Kafka, making possible this polling.
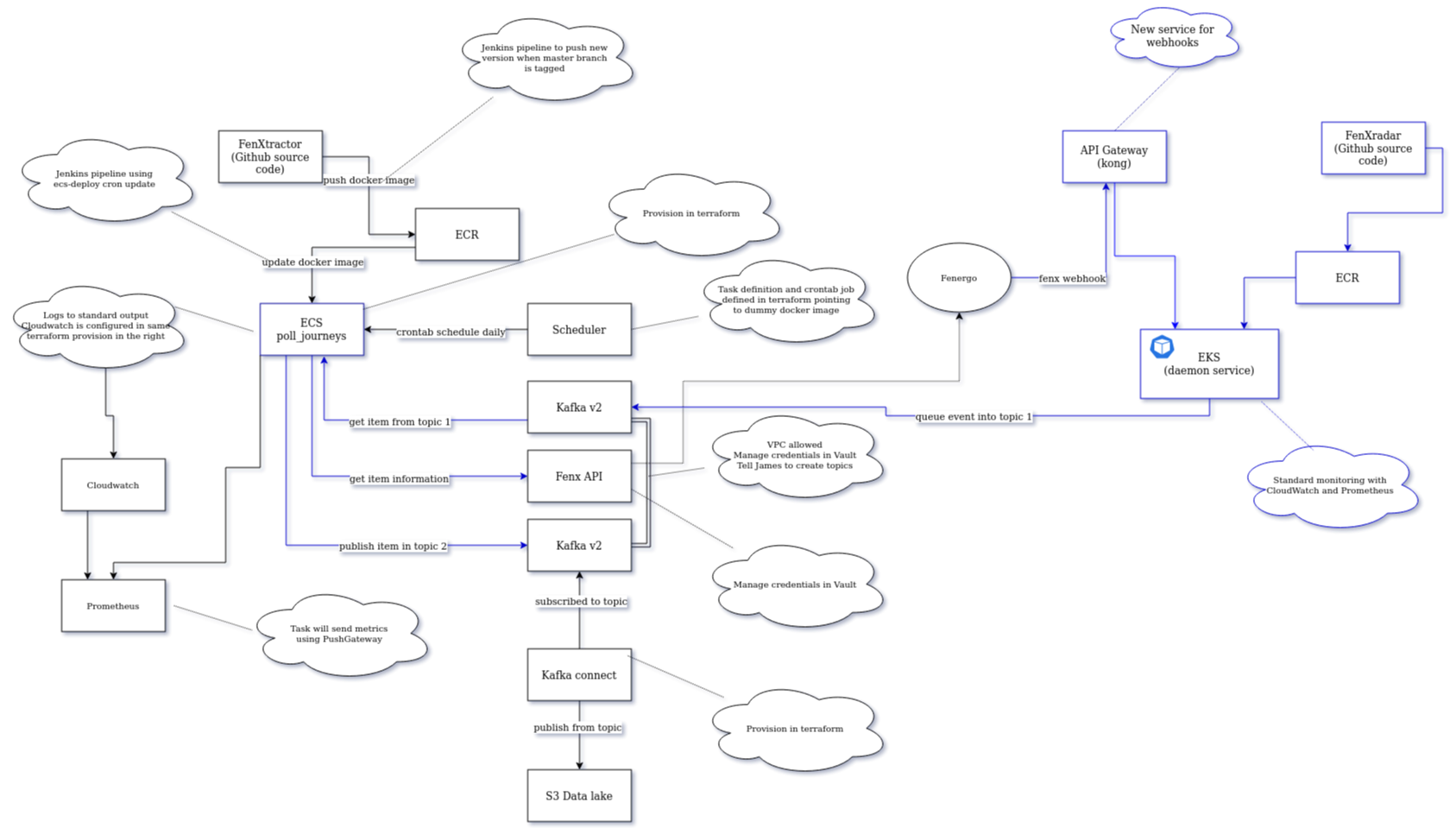
Implementation steps
-
Configure webhook listener in Kong: A service will be configured using a plugin that allows establishing the webhook listener. Request include HMAC signature that the service needs to validate.
-
Create new topics in Kafka: New topics will be created to store the requests from webhook (topic 1) and the detail of journey status from FenX API (topic 2)
-
Service processing requests from Kong to Kafka: New repository FenXradar will implement a FastAPI application that listens to Kong requests to receive filtered legitimate webhook requests. The backend will synchronously try to write the requests to Kafka's "topic 1", to allow polling in the current stage, or a future real time consumer on a next stage of implementation. Optionally, backend could enrich the request from webhook to include needed additional information (for example, at the moment I am writing journey identifier is not sent explicitly, only contained as part of the relative url, and we might be interested on this).
-
Include metrics exporter in service: Prometheus metrics and alerts will be configured based on service metrics.
-
Create polling script to feed Journeys information: Existing repository FenXtractor will implement a separate cron job hourly to get journeys updates and send them to Kafka "topic 2". It just needs a new script file where the steps of requesting FenX API for the journeys pending in "topic 1" for getting detail to send to "topic 2" in a pretty similar way it already does for entities polling.
The messages in "topic 2" will be moved into data lake using kafka-connect.
However, "topic 1" can be considered as a queue for async processing journeys, not relevant for data team nor data lake.
- Include push metrics in the new cron job: In the same way metrics and alerts are implemented using "Push Gateway" in the polling of entities, they will be added for new cron job of journeys.
Error management
Error in the different services could appear. The expected scenarios will be managed by applying:
-
If FenX webhook receives error response after 4 retries, webhook is deactivated, but still queuing events. Reactivation will be managed manually after root cause is solved in our end. This will be detailed in a runbook and will be our main choice for contingency.
-
If Kong fails forwarding request to FenXradar, it responds error to Fenx webhook producer, triggering the behaviour defined in previous point.
-
If FenXradar service fails queuing a request into Kafka, it responds error to Kong that will respond error to Fenx,
triggering same contingency behaviour again if the problem persists. A punctual failure writing might cause events being queued in a different order than produced, but maintain order is not critical, because when querying full detail of journey from data lake, Big Query will use the timestamp contained for each task in the payload to rebuild history correctly.
The important point here is not losing messages, but not so much when they are processed. Eventual consistency is assumed by consumer (data team).
- FenXtractor service will only commit messages from "topic 1" after processed into "topic 2" to don't lose messages in the polling stage. Repeated failures processing an event would raise alert. How to manage the alert will be detailed in another runbook.
Full description of how FenX Webhooks behave can be found here. With respect of the contingency method commented, the descrition provided is the following: * If the clients HTTP endpoint times out or returns an error, FenX will use a stepback retry approach, 4 retry attempts will be made at 2, 4, 8 and 16 minutes consecutively. * If all retries fail, the webhook is automatically disabled (no delivery attempts will be made until it's manually enabled via the API). The event notification is added to a dead-letter queue and an AWS alarm is raised. * Disabled webhooks are still queuing events so as soon the endpoint is up and webhook is enabled, all the notifications will be delivered in proper order (actual delivery process will start as soon as webhook receives next event).
Service Ownership
New service FenXradar and the extended service FenXtractor are owned by DIO team.
| New Service | Service Name | Service Owner |
|---|---|---|
| Yes | FenXradar | DIO Team |
| No | FenXtractor | DIO Team |
Alternatives
Implementing a tactical solution in the same way we did for phase is not really possible since API doesn't provide an endpoint of journeys modified in a period. We could query over all entities details to bulk all information in data lake where it can be compared where are journeys modified, but the performance of that would be poor and degrading with the number of entities.
There are variations that could be introduced to the strategical solution proposed:
-
Usage of API gateway could be avoided, but then security policies needs to be added to the service. We envision that the usage of this model should be followed by other webhooks currently existing in our ecosystem and those to come.
-
Getting request from webhook and send it without modifications to Kafka could be performed directly with Kong. But we prefer the flexibility and the control provided by having the specific separated service. Flexibility in terms of being able to do enrichment or any other transformation or operation. And control being able of monitoring separately, for example.
-
Using a queue to async processing hooks in the service might be preferred in case of further processing of the hook needed for not delaying response back. It would require additional management of error scenarios while processing the queue apart for the additional infrastructure depending on the broker selected.
-
The proposal includes implementation of the new service in EKS, but this shouldn't make any difference to the service, and it is selected for being more aligned with Ebury prospects.
-
The full strategical solution would need a consumer of the first topic allowing real time communication with data lake after retrieving detail of journey. Making this intermediate solution allow us deploying a first solution to the issue and leaves both processes (entities and journeys) to be moved to a real time consumer in a separate step.
Caveats
FenX only supports the configuration of 10 webhooks. We currently have 1 webhook configured for Salesforce and this would be the 2nd, so, no problem at the moment.
Using same instances in Kong for all endpoints could provoke that an outage in one would affect the others. This is something API owners need to consider when adding the new endpoints for webhooks, not only the one on this project.
Operation
New services will not have impact on existing operations.
Security Impact
Webhook messages include HMAC signature using SHA256 hash of a secret shared with FenX at the moment webhook is created to ensure legitimate origin.
Besides, endpoint exposed externally for webhook by Kong will include the existing security and traffic provided by the tool.
Kafka events are encrypted in-transit (TLS) and at rest (MSK) and the topics will have access controls.
Performance Impact
The throughput of journeys modified hourly is not expected to be massive in the usual daily work. However, there could be eventual bulk operations from Salesforce team (backfills, CRR releases, syncs from Salesforce), that would produce peaks in the number of Journeys.
The expectation in these scenarios could mean having hundreds of thousands of events in a period of hours, producing same number of messages in Kafka.
FenX API doesn't provide bulk endpoints, so, this operations would mean a batch of individual operations. On one side, it is FenX there is a dependency with how FenX will manage those inputs to produce the events hooks. On our side, Kong gateway can handle the requests via its ALB, and the service will need to manage writes into Kafka with the proper monitoring.
This will also produce delays since the event actually happens until the information is place in Data Lake, but delays
are not a problem as exposed before in Background section.
Data Sources
-
Input data sources: Fenx
-
Transformation requirements: Service will only enrich with JourneyId if needed. It might not be needed.
-
Output data: Kafka
Deployment
New job in FenXtractor service will be firstly added to the current infrastructure as a separate ECS Scheduled task to be added via terraform.
NOTE: Migration of FenXtractor to Kubernetes is proposed to be done in a separate epic, but we need to take into
account that scheduling jobs is not yet between platform catalog, and support for it is limited.
Service FenXradar will be deployed in the Kubernetes infrastructure provided by Platform.