ISO Migration - Inbound MVP - File reading using Autoclient
Reference Documents
| Reference | Document Location |
|---|---|
| COP001 | ISO Migation - Inbound MVP PRD |
| COP002 | Tech analysis |
| COP003 | Diagrams |
| COP004 | Swift-Gateway vs ACBalancer analysis |
| COP005 | Swift-Gateway and ACBalancer Tradeoffs |
| COP006 | Autoclient docs |
| COP007 | File examples |
| COP008 | Master RFC Draft - MVP0 |
Glossary
- FXS: FX Suite
- FIN files: Files currently used by SWIFT to transport MT messages (text-based, proprietary encoded)
- IA files: New standard of files proposed by SWIFT to transport MX messages (XML-based, open standard), also known as InterAct files.
- SW-GW: Alias for Swift Gateway
- Inbound: refers to the direction of traffic, meaning that this RFC only considers the files that Ebury receives from the Swift network
- EMP: Ebury Mass Payments
- LAU: Local Authenthication, a method SWIFT uses to digitally sign their files
Problem Description
ISO 20022 is an ISO standard for data exchange between financial institutions that is being implemented in various financial market agents and clients that we use today. Today our database, our systems and our processes are based on SWIFT MT messages and we must be migrated to the new SWIFT ISO 20022 CBPR+ format, also known as MX format. Adhering to this new format is not a straightforward change.
This document will present the first component that will be developed within the new architecture to meet the business requirements, focusing in the new incoming flow.
Narrowing down the scope
The first step to integrate with the SWIFT network is to develop a Gateway responsible for consuming the files delivered by the network to Ebury.
In this RFC we’ll be detailing a component of the incoming flow called Swift Gateway.
What Swift Gateway IS: A pass-through, low-level interface between Ebury and SWIFT, allowing connection between the 2 players using different technologies (SWIFT uses SFTP, Ebury uses Kafka).
What Swift Gateway IS NOT: A domain connector or transformer of any kind. It will not apply filters or any type of business logic on the incoming files.
Background
Part of the background below was already explained in the Master RFC, but we'll repeat some parts here to make this RFC more consistent.
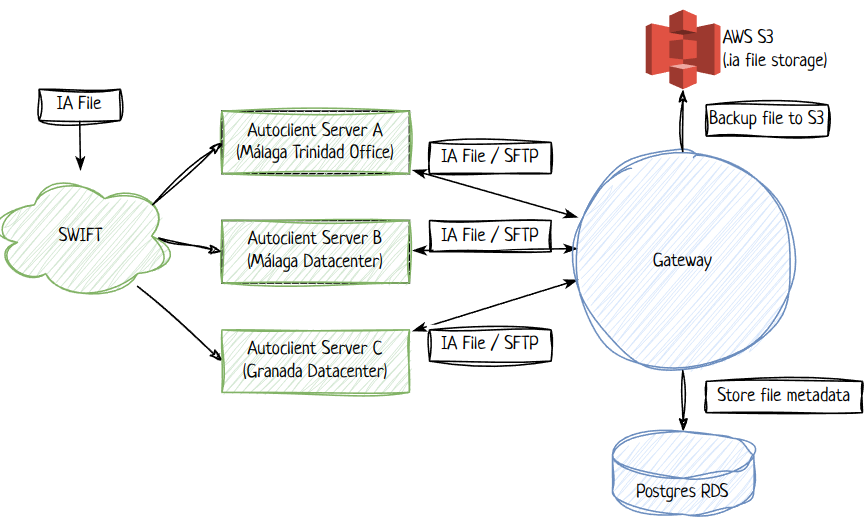
Our communication with the SWIFT network is done through exchanging files, using SWIFTs own file server called “Autoclient”. Ebury access Autoclient servers through SFTP protocol. Each Autoclient server is located physically inside Ebury premises (not in a cloud environment), and we currently have 3 of them.
For redundancy, there are multiple instances of the SWIFT Autoclient software running on different physical servers. Each SWIFT Autoclient retrieves the same files from SWIFT. The gateway is responsible for retrieving a file and deleting the replicas from all instances of the SWIFT Autoclient.
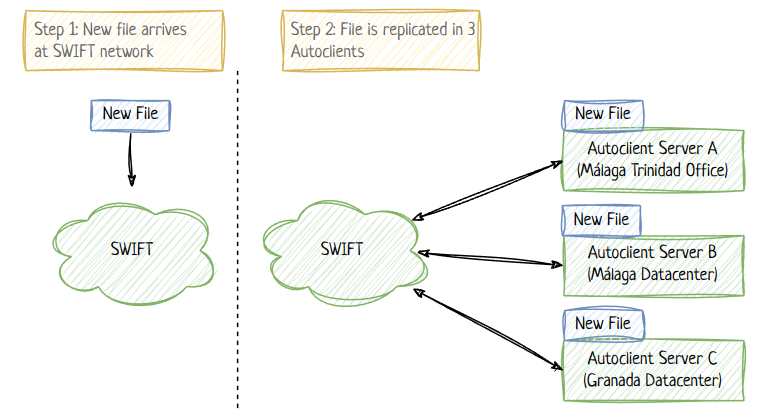
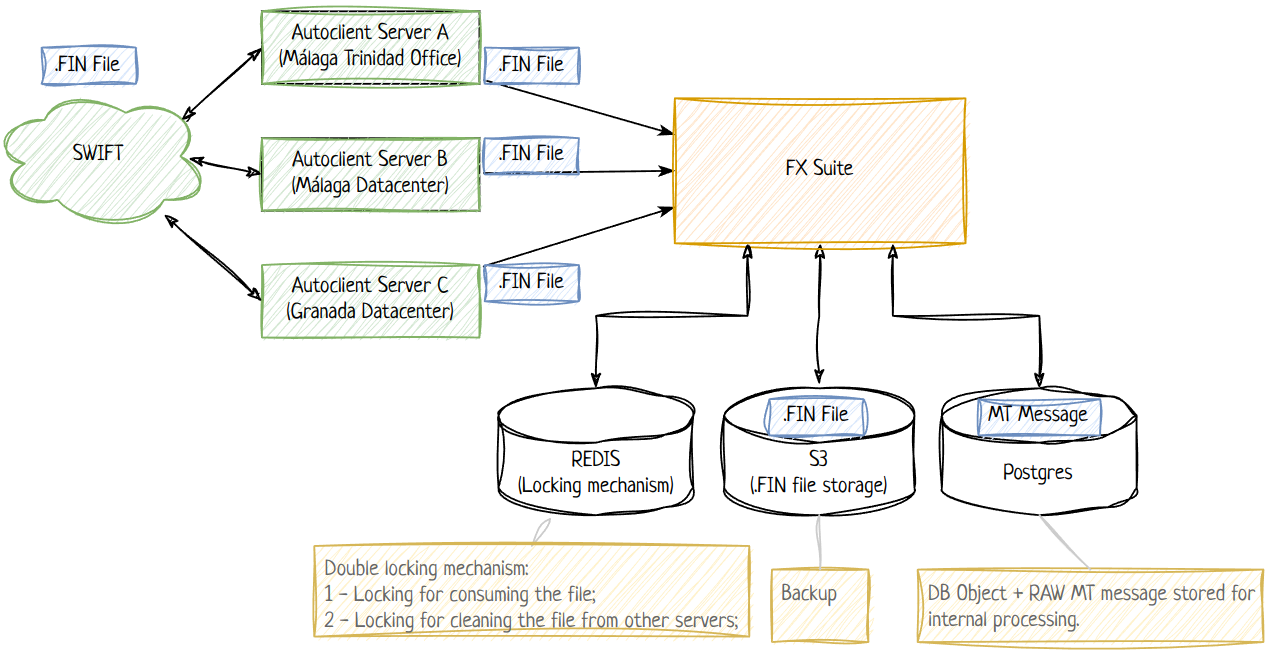
The SWIFT network delivers FIN files (which packages MT messages) to Ebury, through a service called Autoclient. The current stack used at Ebury for the INCOMING flow is served by 1 legacy application, FX Suite (aka FXS), which is able to read these .FIN files and the SWIFT MT messages inside the FIN files.
For each file that FX Suite currently reads, it uploads a copy to S3 and saves a copy in its own Database. Since FX Suite has several daemons that runs reading from the same directories, a locking mechanism was implemented in REDIS to avoid 2 daemons consuming the same file.
FX Suite is also responsible for deleting the files that are replicated in the extra servers, so if it consumes a file from server A, it will delete the file from servers B and C.
The SWIFT ISO 20022 migration project, in the context of Incoming Funds, proposes 2 changes:
- The messages will be changed from MT (text-based, semantically poor) to MX (XML-based, ISO 20022 standard, semantically rich);
- The transport mechanism of these messages will be IA files (InterAct files), and not FIN files anymore;
InterAct files do not transport MX messages directly. The ISO messages are embedded in an envelope (called DataPDU) that contains information about the source and destination financial institutions of the message, such as the BIC code.
This DataPDU envelope is SWIFT-specific, and unrelated to the ISO 20022 format.
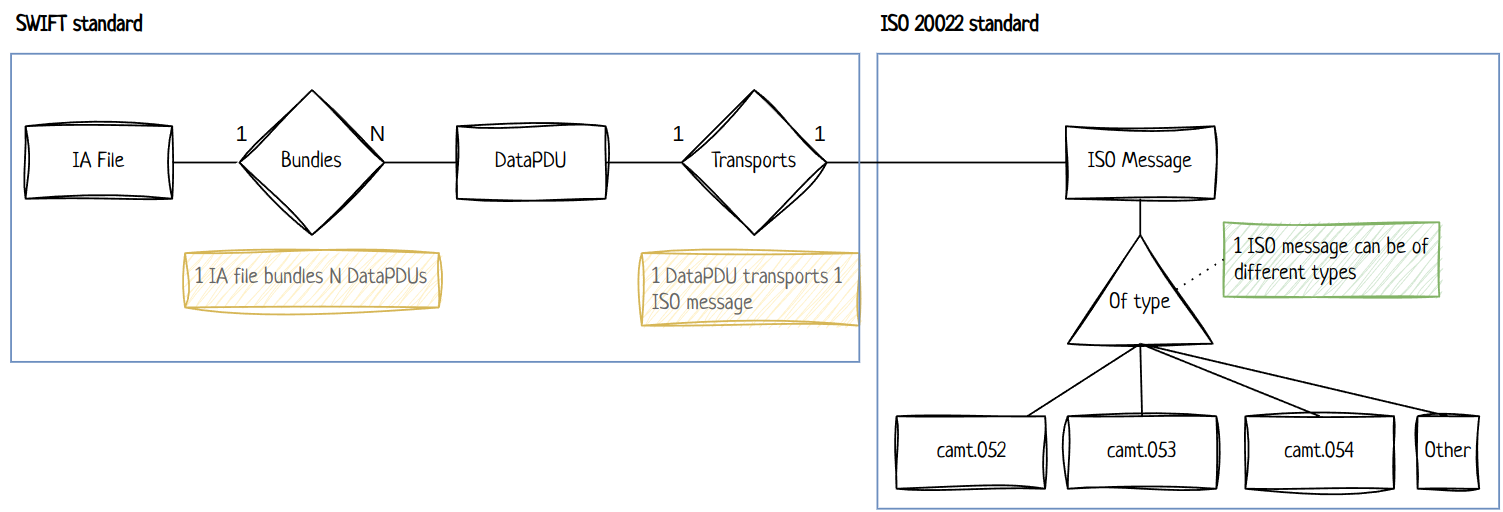
The DataPDU is important to us because there are business rules based on the BIC code information and possibly on other fields that SWIFT makes available, and ISO doesn't.
Solution
An overview of the whole architecture can be seen in the Master RFC Draft document.
Ingress File Traffic
The SWIFT network will deliver the InterAct files to the same Autoclient servers that FIN files are delivered today, using SFTP protocol, and replicated across all three servers we have:
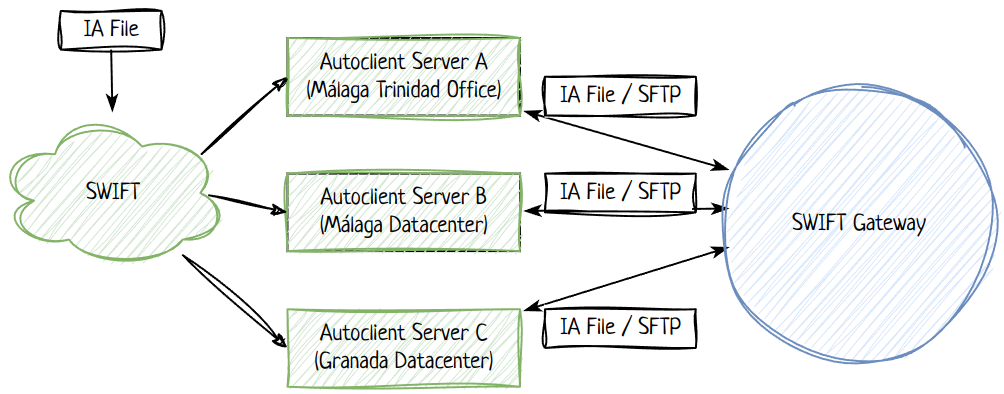
The SFTP protocol does not provide a notification mechanism, hence we need to poll the SFTP servers to detect new files.
When a new file has been detected, the service will
- download the file from the SFTP server;
- upload the file to S3 (for backup/auditing);
- store metadata about the file (path, size, hash, s3 bucket and key) for auditing purposes;
- delete the file from all 3 Autoclient servers;
The InterAct files are considered private resources for Swift Gateway, given the fact that they're just bundles of DataPDUs, and of no interest to downstream systems.
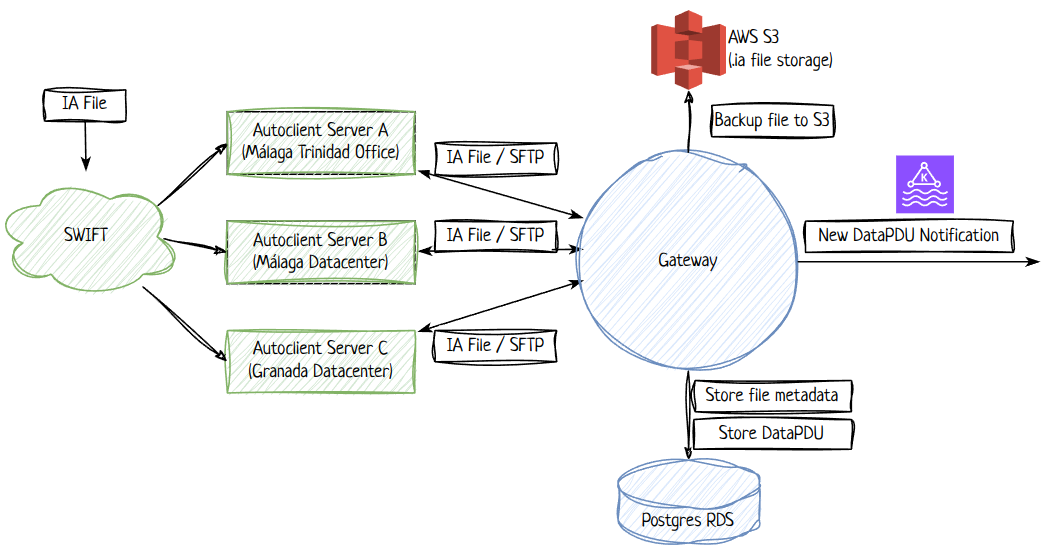
After acquiring the file, the service will extract the DataPDU messages and notify downstream systems about each new DataPDU.
Each part inside an InterAct file consists of:
- Binary header with 31 bytes: a prefix byte, the length encoded in 6 ASCII-character decimal digits, and 24 bytes of LAU signature;
- UTF-8 encoded XML payload which is the DataPDU itself;

At this moment the service will:
- Break the file into DataPDU blocks;
- Validate the consistency of each DataPDU by checking size, LAU signature and checking if the DataPDU is a syntactically valid XML document;
- Calculate the unique but deterministic key (i.e. filename + DataPDU index in the file) for each DataPDU. This is necessary for deduplication in the consumers due to the at-least-once notification strategy;
- Store the DataPDU in the database along with the generated key;
- Publish the DataPDU to Kafka.
Note: as different banks will switch to the ISO format at different times, there will be a period when we receive both FIN files and InterAct files. Swift Gateway will only download and remove InterAct files, it will leave the FIN files on the Autoclient servers, letting the existing FXS service handle them. Similarly, FXS only moves FIN files. The files can be distinguished by filename extensions (.fin / .ia).
Egress File Traffic
To send files to the Swift network, Swift Gateway
- receives DataPDU XML messages in a Kafka topic along with a unique request ID and optionally some labels - both the unique ID and the labels will be used in responses about the request;
- calculates the InterAct header signature and LAU signature
- constructs the InterAct file content by adding the 31-byte binary header in front of the XML content;
- generates a timestamp-based filename;
- generates LAU file content
- Selects one of the AutoClient servers - using round robin
- inserts a record about this file upload operation in the DB storing the
- request id (unique)
- filename (unique)
- labels (blob)
- AutoClient Server selected
- the DataPDU message read from Kafka
- state: NEW
- [state==
NEW] uploads the LAU file to theemissionfolder of the selected server - Swift will only read/move this file when it finds the corresponding .ia file, hence this operation doesn't need to be atomic - [state==
NEW] uploads the InterAct file to the selected AutoClient server - writes with a.tmpfile extension in theemissionfolder - if [state==
NEW] then it - locks the row (
SELECT ... FOR UPDATE) - we explain later why - changes the state to
MOVING FILE - renames the InterAct file from
.tmpextension to.iaextension - the (kind of) atomic file rename operation can avoid race conditions with the Swift-side reading process - updates the file-upload operation DB record with state
UPLOADED - if [state==
UPLOADED] then - uploads the file with the same filename to an S3 bucket - for backup/auditing
- updates the file-upload operation DB record with state
IN S3 BUCKET(commmits and releases the locked row) - commits the Kafka message
Summary of state transitions:
NEW > MOVING FILE > UPLOADED > IN S3 BUCKET
The described solution can scale with multiple parallel upload processes as long as the input Kafka topic is partitioned.
Error Handling
The upload process might fail at any step. When that happens the worker either restarts, reconsumes the same Kafka message, and performs the entire upload process again, or leaves the upload operation DB record in an unfinished state, raises an alert, commits the current Kafka message and consumed the next one. All steps can be handled either in an idempotent manner or orchestrated by tracking the state.
| Step | Idempotency Strategy |
|---|---|
| Signature calculation, constructing file contents, generating filename, selecting AutoClient server | recalculates every time - cheap in-memory operation |
| Inserting DB record about the file upload | the unique constraint guarantees that we cannot do that twice; should that exception happen, we read back the DB record and use the values stored there (i.e. filename, selected AutoClient server, upload state); should the file-upload operation state we read back be MOVING FILE, we raise an alert as this needs investigation (see Incident Handling), and commit the Kafka message |
Uploading LAU and the .tmp InterAct file |
if the file exists, overwrite it or remove it and upload it again - the file might be incomplete |
Renaming the InterAct file from .tmp to the .ia filename extension |
we only get to this step when the upload operation was found in NEW state |
| Upload to S3 | we can upload the same content with same key repeatedly - this should happen very rarely so we don't worry about the cost |
| Commit Kafka message | if it was successfully commited before, we won't see the same Kafka message again |
Incident Handling
We want to avoid sending the same file twice insted of relying on idempotency on the SWIFT side, for reasons:
- The lack of a file in
emissionfolder could mean (1) we never sent it or (2) Swift has already processed the file and removed it. - The communication pattern via FTP is complicated.
- There is no real protocol-level contract, and the specs are vague.
- In the end, the account may be debited twice.
- We can't safely rely on "already seen" error response codes to assume the request has indeed been processed before (what would be that set of error codes exactly)?
- In case we receive an "already seen" response code, before we treat that as an error, for how long should we wait to get an ACK about the previous upload attempt? Are ACKs reliable, will we always receive them?
When there is an error during the renaming of the InterAct file from .tmp to .ia or the saving of the upload state to DB right after that, then
- an engineer needs to check the logs what happened exactly, can we conclude that the FTP
mvcommand was successful, and only a subsequent step failed? - in this case update the DB record to stateUPLOADED(with a DB migration) - if the fate of the FTP
mvcommand cannot be established by inspecting the logs then we need to reach out to the banking partner or SWIFT to check if they received the file - if they did not receive it then update the upload status to
NEW(with a DB migration) - if they received it then update the upload state to
UPLOADED(with a DB migration) - this way the upload to S3 will still be performed
At start-up, the workers query the DB and execute (continue) any operations in NEW or UPLOADED state. There can be multiple concurrent workers, and this is why we lock the upload operation DB row.
Handling ACKs and NACKs
After a successful file upload we can receive positive and negative acknowledgements from SWIFT network. They will typically embed the original message (or at least the important references that allow the sender to recognise them), and in case of a rejection an optional reason code and additional information. Instead of the usual Message XML element inside /DataPDU/Header there will be one of TransmissionReport, DeliveryNotification, DeliveryReport, MessageStatus, etc. (see XMLv2 specs). SwiftGW doesn't need to read and interpret this information, it needs to forward the DataPDU as is to the next downstream service. The chosen strategy today is to keep all types of DataPDUs in the same, single Kafka topic. The only reason SwiftGW might want to know the message type is to produce metrics.
Handling error files
Error files are in response to an InterAct file that the receiving side could not read or understand, failed some integrity checks, etc. The error file uses the same filename as the original file with the added .err file extension. SwiftGW saves the original request ID, labels and the generated filename when uploading an InterAct file, so using the filename, it can find the original request and communicate all that information back to the requestor in a Kafka topic. In most cases the content of the error file is unstructured text. SwiftGW handles the content as opaque payload.
SwiftGW must not read and remove *.fin.err and *.fin.err.lau files from the AutoClient servers, as the old FXS flow still needs those.
Receiving ACK, NACK and error files is normal operation from a SwiftGW point of view and must not trigger an alert. The downstream services will.
DB Garbage Collection
The data in the DB serves only operational purposes. Files sent and received are uploaded to S3 for backup purposes. This means we can keep the DB footprint small by regularly deleting old records from the DB (CronJob). Suggested retention period: 7 days. This implies that any incident (where messages may need to be reprocessed) must be solved within 7 days, which is reasonable for payment instructions and processing of financial records.
Service Ownership
| New Service | Service Name | Owner |
|---|---|---|
| Yes | SWIFT Gateway | COP Team |
Alternatives
An alternative would be to implement the new features using FXSuite, but this is a legacy which Ebury wants to decommission.
Another alternative would be to implement the changes in AC Balancer, but AC Balancer only handles the OUTGOING legacy flow and even though it's a newer service written in Python 3, it's strongly coupled with the FX Suite legacy stack, which we also want to isolate in order to make the decommissioning process easier in the future. The pros and cons of using AC Balancer were described in the tradeoffs analysis document.
The implementation in a new service is also motivated by the separation of responsibility, since we are dealing with another nature of files and with the idea of creating a gateway with SWIFT and not with Autoclient (even if at the moment we are using Autoclient).
- We have considered using Benthos, however we didn't find it fit for this project for reasons:
- its
sftpinput produced erratic behaviour (permanent disconnection after even a single connection error), and none of the Benthos healthcheck endpoints, nor metrics correlated with the situation, so we could not even use those with K8S probes to at least restart the service, and we don't know a way to add a reliable heartbeat mechanism such as the one suggested for the problem with paramiko - our use-case is not a typical one: dealing with file replicas on 3 physical FTP servers (the typical use-case would be to have one endpoint/interface and let the cloud infrastructure provide high-availability), hence not many other Benthos users out there are expected to face the same kind of problems we have. A cloud solution from Swift is being tested with smaller participants at the time of writing this, and we don't expect that the AutoClient server solution for Ebury will be replaced with a cloud-based, API solution any time soon. (If there is appetite, maybe we can look at Benthos again when that happens!)
- its
- to be able to (1) understand how exactly Benthos is supposed to work under the hoods, (2) fix bugs we find, (3) add more metrics and logs where we today have no clue what's happening inside a standard Benthos input/output plugin (e.g. what S3 request URL is being used that fails), or to be able to define reliable K8S probes, we need to dig into Benthos code but few people in Ebury know golang. Ebury doesn't have a support agreement for this product.
-
Kafka Connect SFTP Source and sink connectors
- the main reason we discarded the idea at the very beginning of the project is that we had concerns that a file wouldn't fit into the Kafka message size limit, however since then we have learned that with Avro encoding, we can specify the compression type, which typically results in ~2-magnitude smaller payload size, giving us roughly a 100-200 MB max raw file size that we could still put into a Kafka message.
- we expect the same problems around handling file replicas from the three FTP servers, as with Benthos
Caveats
-
FX Suite currently contains code to consume IA files in order to generate some specific metrics - this can lead to concurrency issues between the new Swift Gateway and FX Suite, if both are reading from the same SFTP folder in Autoclient
- Initial analysis points that this part of FXS code is isolated into a specific daemon running on ECS, and we can set this daemon to run on ZERO machines, effectively eliminating the concurrency problem, without changing any of the FX Suite code;
- If this is not possible for any other reason, we can add a switch or feature flag in FX Suite to enable or disable this code in production. This change shouldn’t be big, but it will be an important part of the rollout plan;
- FX Suite also removes the IA file that has been read from Autoclient;
-
Python code that connects to SFTP servers usually rely on a library called Paramiko. Paramiko is known to be unreliable specially regarding timeouts, and in some of our legacy applications we had to develop workarounds brute-forcing timeouts using the Operating System signals to avoid the process to be infinitely frozen. A generic solution to mitigate occassional, unexpected lock-ups by blocking function calls into third-party libraries can be mitigated by the use of heartbeat files and K8S probes (example used in existing services here, here and here).
-
This solution needs a reliable way to raise alerts. Using Promethues's poll strategy is not reliable, as the process may crash before the metrics could have been scraped. This is a generic problem for which Ebury has not found a best-practice yet at the time of writing and is outside the scope of this blueprint.
Operation
The service will be deployed in a private network (Kubernetes cluster) and it will communicate through SFTP with Autoclient and Kafka topics with other Ebury systems.
In the initial days of deployment the service will be monitored by the COP team, but over time as operations begin to flow, it will be handed over to the Support team, with the proper alerts in place and runbooks defined.
This service is expected to run under Ebury Core infrastructure, and MUST NOT run under Ebury Mass Payments infrastructure, as EMP does not have any Autoclient instance.
Security Impact
No impact is expected on the existing Alliance Lite 2 service from SWIFT.
The files received from SWIFT will contain PI data related to clients, and therefore MUST NOT be leaked through logs, for example.
All received files are a special kind of XML format that SWIFT calls XMLv2, that are standard XML files, but prefixed with a binary header containing integrity information about the file. Our service will validate if the file is consistent before processing the file and passing it through to other Ebury Services.
Since the file contains only XML, we’ve checked with security (SP-19179) and there’s no need to scan them for viruses.
Points of attention:
- XML files are a possible attack vector, thus the service will need to defend itself against possibly malicious XML files;
- There is a way to mitigate this attack vector by using proper libraries and protecting the code accordingly to the notes below:
- The number of files and expected average size is not clear yet, but all files will be stored internally into a S3 bucket, so we need to plan capacity and long-term storage accordingly, avoiding a possible DoS attack (voluntary or involuntary) due to the amount of files exchanged;
- No caching will be involved in parsing the files;
For each processed file we’ll store metadata about it, and one of the important fields is a hash (SHA-256) of the file, which we can use retrospectively to check for modifications and inconsistencies;
Connections to the Autoclient servers are done using login+password, both stored in Vault.
Performance Impact
In the context of Incoming Funds, the most similar workload that we have today is the one from FX Suite that handles MT940 and MT942 messages.
At the risk of over-simplification, the workflow of a MT940 is similar to a camt.053, and the workflow of MT942 is similar to camt.054 and camt.052.
That means that for each new entry in one of Ebury accounts we expect to receive a file that contains a camt.054 (or camt.052, depending on the bank), and for each account Ebury has we expect to receive one camt.053 daily.
In a period of 24 hours (October 10th, 2023) we had 2.400+ MT 940 messages and 12.500+ MT 942 messages, by checking Kibana logs. This is within a typical daily volume if we check the last 30 days.
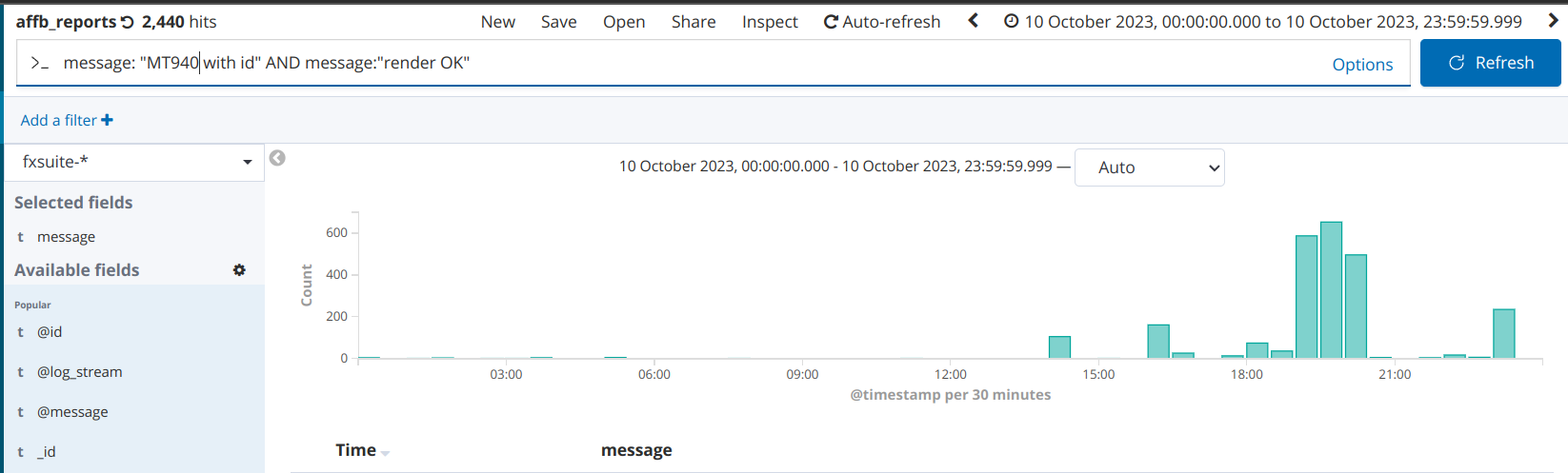
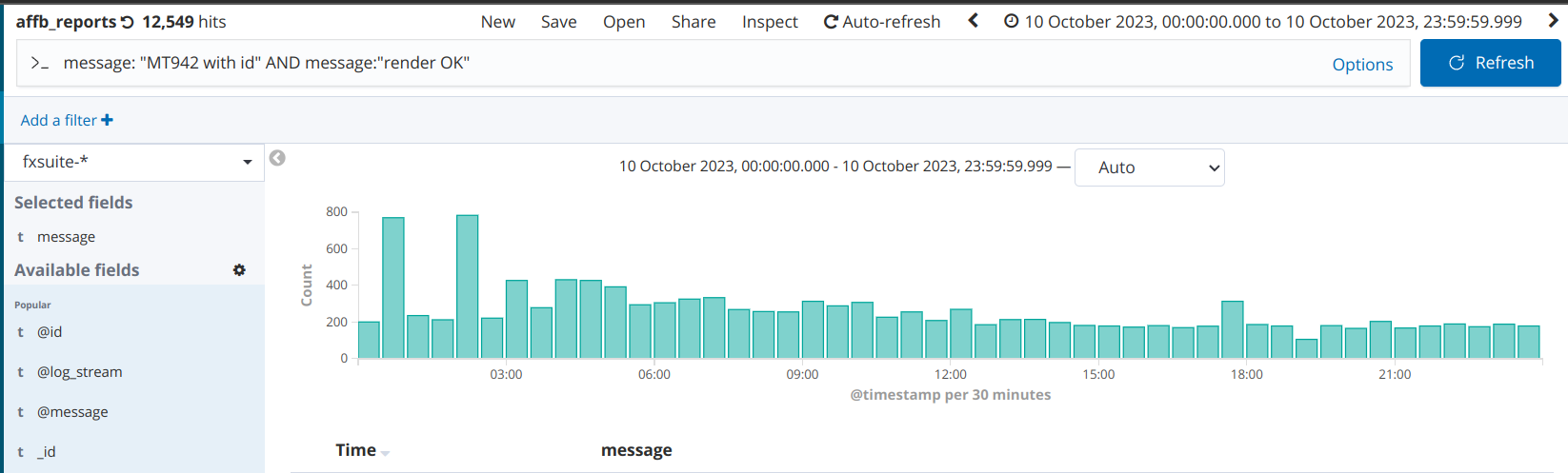
There’s also an useful dashboard showing the current flow of MT942 messages. Focus on the "Received MT942" panel, as it shows how many messages we received and had to analyse.
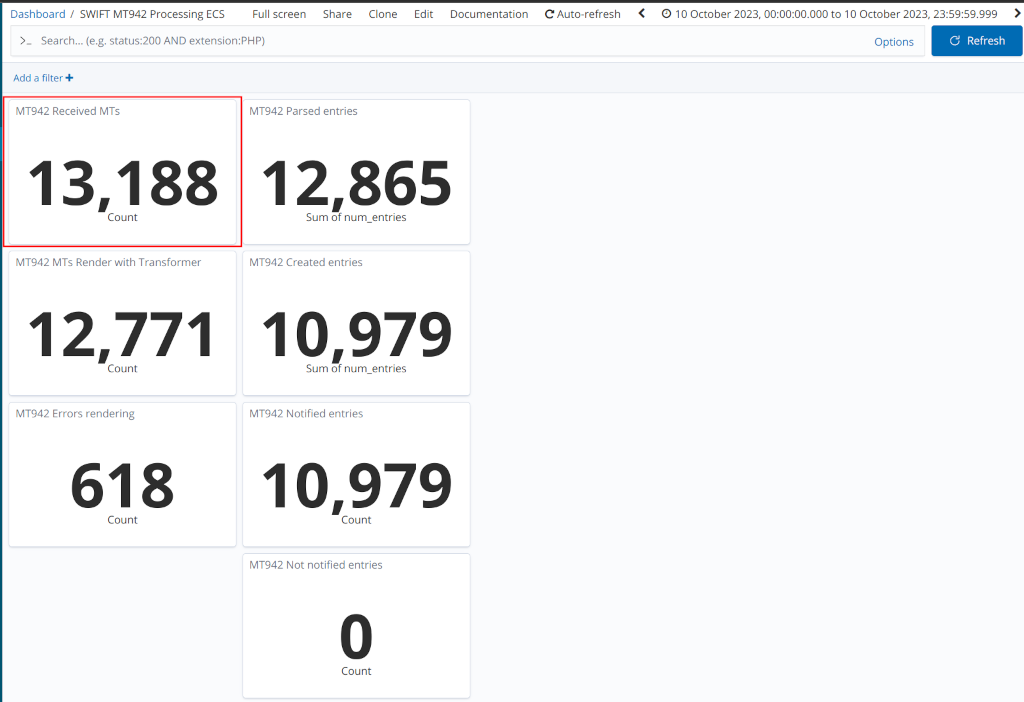
We expect about the same amount of files for camt.054, camt.053 and camt.052 as described above daily, as the focus is similar which translates roughly to:
- 12.000+ daily messages combining camt.054 and camt.052;
- 1.500+ daily messages of camt.053;
We also expect an increase in size, as the legacy MT message format is more compact than the ISO 20022 XML format. Without actual production data there’s no way to have a real value, but we can estimate from the samples below:
- 1 MT942 file with a single entry has 500 bytes;
- 1 InterAct file, containing 1 camt.054 message with a single entry has 13.000 bytes;
- The camt.052 message is similar to camt.054 by ISO standard;
Taking only these 2 files into consideration we have these estimations:
| Scenario | Rationale | Final Size |
|---|---|---|
| MT942 | 12.000 messages/day * 500 Bytes/message | 5.7 MB/day |
| Camt.054 + Camt.052 | 12.000 messages/day * 13.000 Bytes/message | 148.8 MB/day |
That’s a 26x increase in size.
There’s also a seasonal component on these messages, as historically at the end of the year the volume of Incoming Funds messages increases a lot. Unfortunately we don’t have hard statistics regarding the volume, as we’re storing this information only in Kibana, but this is common knowledge inside Money Flows and Operations teams, as they need to deal with larger volumes of fund reconciliations.
In order to analyse our scaling needs for future stages, the following metrics are planned to be collected:
- Number of files received daily;
- Total file processing time (From receiving to sending them to Kafka and archiving them);
- File size;
- Idle time;
- Bandwidth / Download speed;
Data Contracts
The IA files are received in this format:

The contracts will be created following the structure established by ISO 20022 itself. We will publish topics with the complete message (.ia) and topics with the respective DataPDU's.
The InterAct XMLv2 files are defined in Appendix B of AutoClient 1.4.0 for Alliance Lite 2 User Guide.
Inside the InterAct XMLv2 files, there will be ISO 20022 messages.
Swift Gateway will be a producer of the following Kafka topics: - events.swift.incoming-file - Will contain messages notifying that new IA files are ready for consumption; - Each message will contain metadata already described in the proposed solution; - The messages will NOT transport the whole file, only a reference to the S3 location; - There is no need for infinite retention; - events.swift.incoming-pdu - Will contain messages notifying about DataPDU inside each IA file; - Each message will contain the whole DataPDU; - The DataPDU is limited by SWIFT standard to 999.999 bytes fitting inside a kafka message; - If needed, we can activate compression in AVRO schemas reducing the payload; - There is no need for infinite retention; - events.swift.incoming-error-file - Contains: - error file content (unstructured text) - original request ID - original request labels
Swift Gateway will be a consumer of the following Kafka topics: - events.swift.outgoing-pdu - Requests to turn DataPDUs into InterAct files and upload to AutoClient - The requests contain: - DataPDU payload - request ID - labels
Data Sources
SWIFT network is the main data source, providing files through Autoclient server (via SFTP protocol).
Deployment
The service will be deployed in our Kubernetes cluster, meaning it MUST support concurrency, as there’s expected overlap between the current pod and the previous pod in a deployment.
This is described in the Developers Handbook and it’s a reasonable non-functional requirement.
Dependencies
No dependencies with external systems at the moment.
Based on RFC Template Version 1.1