Helm
Describe the usage of Helm charts in deployments and release process for Ebury platform services in Kubernetes.
Problem Description
Ebury platform is being migrated to a new infrastructure on top of Kubernetes. Tooling for releasing code will be needed. Furthermore, there are requirement for having immutable artifacts across environments and for being able to spin up a whole new environment at any time from those artifacts.
One of the primary objectives of the migration to kubernetes is to allow development teams to deploy new services autonomously in a self service model. So far, we have a time to production for a new service built from scratch of several weeks, but we need it to be less than one day.
Background
In ECS deployments, the CI pipeline is coupled with CD. The deployment is imperatively done from a Jenkins pipeline which tells the ECS cluster to deploy the version the CI pipeline has just built. This approach presents several problems as already outlined in Services deployment manifest blueprint.
In addition, the task definition for a service, including the IAM role for the service and the environment specification is defined as part of infrastructure code, meaning that every new service needs to be included in the infrastructure code in the first place even if the service makes no use of any AWS service. The same happens for the inclusion of a new environment variable or a change in the resources (CPU, memory) requested by the task.
The main advantage of having the task definition in infrastructure code is that output from Terraform modules can be used directly as input for modules (e.g. the URL for RDS connection, the ARN for an SQS queue, etc.). Any change in infrastructure is reflected in terraform apply as well in the environment for the task definition.
Most of the services in ECS follow the same pattern, although some experimental approaches, splitting CI form release as specified in the mentioned blueprint has been followed with success in some projects:
- Monorepo approach in Events project
- Deploy through manifest repository in API and Events projects
Demo and Sandbox deployments follow a similar approach, deploying environments from a specification in a manifest, but with different git branches for each environment instead of different manifest files in the same branch. Environment variables in those environments are defined in the manifest, but that implies that there are three different places at the moment where environment needs to be specified (local ED2K, demo/sandbox and staging/production)
Platform vs Infrastructure
In this document, the terms platform and infrastructure are used. They are not synonymous, and they are not interchangeable.
-
Platform is the set of services and tools that form the Ebury Transactional Platform. Its specification is in continuous evolution with changes driven by development teams.
-
Infrastructure is the set of cloud resources that provides capabilities to the platform. The platform runs in a infrastructure provided and maintained by the platform team.
For instance, infrastructure could provide database servers as a capability in a Kubernetes cluster, backed by RDS, while the actual database is part of the platform.
Any resource that is created outside the platform lifecycle should be made available in the cluster and accessed in the same way in all the environments, for instance:
- If the infrastructure provides an RDS, the accessible URL for the RDS should be the same in all environments (probably defining it as Service with type ExternalName)
- If the platform provides access to services in the legacy infrastructure (for instance, URL for BOS), the URL should be the same also in all environments.
In order to remove bottlenecks, and in order to achieve the target of having a new service in production in less than one day, platform specification MUST be decoupled from infrastructure specification.
Infrastructure code is owned and operated by platform teams, and development teams should not need to add code there for deploying new services as a general rule.
Solution
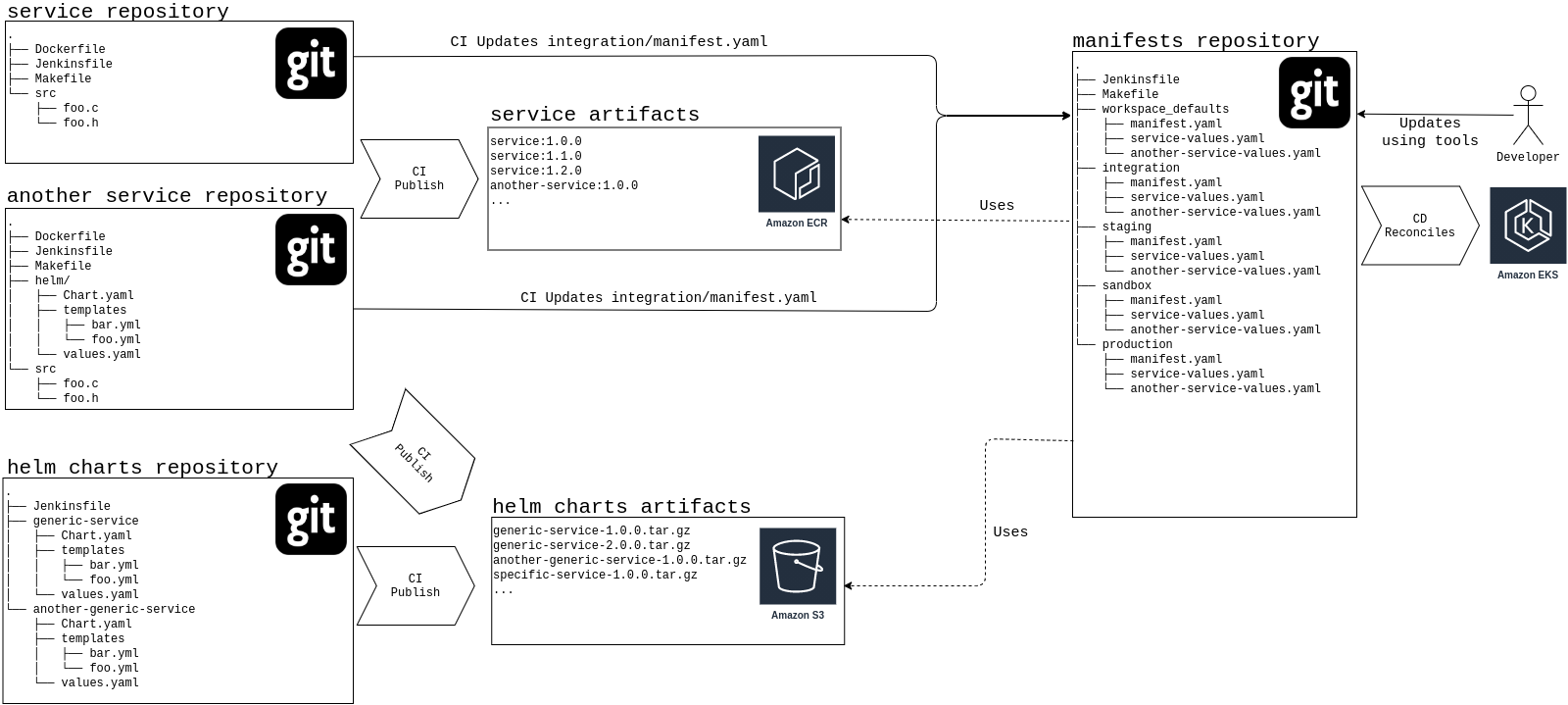
Follow the guidelines in Services deployment manifest blueprint and create a repository with multiple folders, one per each environment.
A release of a service will be either a combination of a Helm chart version and a Docker image version if the project uses a generic Helm chart, or just the Helm chart version if the project is creating its own specific chart, using the chart version for tagging images. A deployment of a service is a combination of the former with a set of values specific for the service and the environment.
The build process for services (i.e the CI) will build and publish all the images defined in a repository, and will update manifest accordingly. The format (and the tool used for manifest deployment) will be Helmfile.
Helm chart building blocks
A set of Helm charts will be provided and owned by the Platform teams as building blocks. A generic implementation using the building blocks will be also provided, as most of the services are considered to follow similar patterns.
However, it will be possible for development teams to define their own Helm charts, or to extend them using the generic Helm charts as [building blocks] by including them as a subchart dependency.
Examples for Helm chart building blocks include opinionated way for defining metrics, alerts and grafana dashboards.
All those generic Charts will be in the same git repository, with a CI job publishing new versions to a Helm chart repository. The current options for this repository are S3 and ECR, allowing us to have authentication configured by default through the usage of AWS credentials.
For those services defining their own Helm chart, utilities in CI will be provided so the charts gets published to the same Helm chart repository.
Both image and tag, together with a set on environment variables that can vary between environments, and also some behavioral stuff like a list of daemons to run, the port where the application is listening, memory and CPU limits, etc. will be values passed to the chart template when specifying a Helm release.
The same charts will be used for all environments, including the development workspace. If the behavior in the development workspace is different (we want to include admin insights tools, debug containers, init containers for data seeding, etc.), it should be configurable through a specific value in the generic chart.
Helmfile
Helmfile is a declarative spec for deploying helm charts. Actual deployment is delegated to helm
binary, while helmfile CLI is in charge of orchestrating the deployment and reconciliation.
It includes tools for generating a plan of the deployment, and updating only the services that need any change in relation with the manifest. It supports some limited templating capabilities.
Altogether, it can be used as a quite simple umbrella for providing a manifest in a format that is understandable by both human and machine.
integration/manifest.yaml
repositories:
- name: ebury
url: s3://ebury-helm-repository/
releases:
- name: service
chart: ebury/generic-service
version: 1.0.0
namespace: integration
values:
- image: service
version: 1.1.0
- ./service-values.yaml
- name: another-service
chart: ebury/specific-service
version: 2.0.0
namespace: integration
values:
- image: another-service
version: 1.0.0
- ./another-service-values.yaml
Release
The update for versions in the integration environment will be done automatically by CI right after an image is pushed to docker registry, on events defined by each team (either a tag or commit to master branch, although changes in master branch is the preferred option). Actually, most of our pipelines are already doing so, and a platform-manifest repository that is used for Demo and Sandbox deployments. The manifest is currently being updated with methods available in Jenkins library, so a change in the manifest format or publishing to multiple manifests would be easy to distribute.
By using Helmfile, A new version of an app will be a new helm release with a new value set defined in
the manifest.yaml updating the container images on deployments. Kubernetes api will not be used for
updating deployments.
Helfile also provides the ability to show beforehand the changes between the current helm releases deployed and the ones that are going to be upgraded.
Updates in subsequent environments (staging, production, demo, sandbox, etc.) will be done through Pull Request. There will be tools for creating the PR that will update a given service (or a set of services under a domain) in an environment with versions from a previous environment. For instance, a make target is being used with success in ebury-api-manifest repository:
make move source=integration target=staging domain=fx
The tools will refuse to update a file if the values and environment files specified in the target environment do not include the same keys specified in the source environment. Similar checks will be done in PR verification.
In future iterations, an automated pipeline (instead of human operator) could be in charge of updating the different environments provided tests passed successfully after each deployment. In such a case, the automated pipeline will still operate the releases through commits in the manifest repository.
Rollback
Rollbacks will be deployed in the same way as a release. As the Helm charts are immutable, and the
specific values for a release are contained in the Helmfile manifest, a revert commit with a
subsequent deployment of the changes will have the same effect as a helm rollback command.
In exceptional cases, rollback could be done directly by a human operator with helm rollback
command. However, the next automated deploy attempt will try to deploy again the release, so in case
a rollback is performed manually, the automated process MUST be disabled until the Helmfile state
and the Cluster state are reconciled with the aforementioned revert commit.
Alternatives
Keep current manifest format
Instead of specifying the manifest with the format offered by Helmfile (or other chosen tool), using the current implementation in ebury-api-manifest, agnostic of the platform or the tool used, and then translate the JSON format to the actual deployment file. The advantage would be that no changes are needed in the left side of the pipeline for the services already following this pattern, the drawback being the additional complexity in the deployment, and the possibility of encountering unforeseen limitations in the current format.
Terraform Helm provider
Instead of Helmfile, using the Terraform Helm provider could serve the same purpose with a tool already known by the team.
Until recently, the lack of helm diff support was a considerable caveat, but it has been
implemented recently in the provider. Format for the manifest would be HCL instead of yaml, which is
slightly more difficult to update in an automated way.
It can be argued also that having access to Terraform datasources describing the current infrastructure would be an advantage, but, actually is a bad pattern that couples infrastructure with services.
However, even if for some reason we still need to retrieve infrastructure information, we could still use Terraform datasources just for that purpose, passing then outputs to whatever tool is used for defining manifests.
GitOps operators
Use GitOps operators (ArgoCD or Flux). Although the proposed solution already uses git as source of truth for deployments, it still lacks the reconciliation loop and pull based operations (as outlined in GitOps RFC. However, GitOps operators are complex and additional complexity when a lot of changes are already being included in the platform is not desirable. In addition GitOps adoption is still in RFC phase , but the manifest specification would be a step in that direction.
Caveats
Change in release process in contrast with current ECS is significant not only in terms of the tools used, but also in terms of the required human steps for shipping a change to production.
Operation
CI pipeline will be in charge of publishing artifacts and updating the manifest for integration environment. Reference pipelines and helpers for usual services will be provided by platform teams.
Development Teams will be in charge of promoting changes in the manifest to other environments. Such promotions shall not need any approval beyond the development team.
Development Teams will be in charge of adding new services to the manifest, and updating its values if needed. Such changes will need approval from platform team.
Security Impact
Security in deployments is increased over ECS, as the agents running the CI pipeline will no longer hold permissions for deploying workloads arbitrarily. The pipeline for deploying can be fully segregated from the pipeline for building.
No additional permissions are needed, and there are no changes in responsibilities, as it is already possible for development teams to deploy updates in the workloads running in production.
Auditing for changes included will be clearer.
Performance Impact
N/A
Developer Impact
The release process for the services will change, so developers will need to get familiar with its details. The current documentation will need to be updated accordingly.
Data Consumer Impact
N/A
Deployment
Development teams will initially include their services in the manifest as part of the onboarding of their services in Kubernetes platform.
Dependencies
N/A
References
[building blocks] https://helm.sh/docs/topics/library_charts/