Salesforce to BvD third party service connection
Create a service within Salesforce to directly get the data from the BvD API (third party provider). This project is also known as Pull Data from Orbis.
Problem Description
There are a few challenges to address:
- How to resolve the connection: Direct VS through a side service.
- How to deal with the security: Where to store passwords if any, authentication mechanisms,etc.
- How to process the information: How to translate the BvD API response into actual Salesforce records.
- How to map the information dynamically into our Account object: Keep mapping of values clear and yet flexible so that we can tune and extend the copy without R&D intervention is a little tricky.
Background
Bureau van Dijk (BvD from now on) is our data provider that allows the onboarding activities to be carried out. In essence, from the functional perspective, we need all the legitimate information we can have from any potential customers so that we can evaluate risks and do the onboarding afterwards.
This “pull of data” is literally being done manually. This means that onboarding spends a significant time just doing the import of data into Salesforce before the actual processing/review can even start.
To streamline this process we want to remove the manual steps and automate it. BvD itself provides a Salesforce plugin that can simplify certain tasks, but it is limited and quite inflexible. Unfortunately, it doesn’t meet our specific needs and tweaking it to achieve our goals would require reverse engineering and would be essentially a bad solution. All these conclusions and the corresponding analysis can be found here.
Solution
To address these challenges, we have designed a number of components that will sit 100% on Salesforce. We'll refer to these set of layers as the “Pull Data Framework”:
- A connector to handle communication between systems.
- A mapping engine to translate Salesforce and BvD information back and forth.
- An orchestrator that takes care of the details and handles the operation.
- A toggle to switch the framework on-off.
The first one, the “BVD connector” layer, will take care of the security and connection aspect through an HTTP request. It’s been made following the “selector” pattern so that it is easier for the clients to use it and for devs to read. A UAT recording can be seen here to check how it works.
The second one is to resolve the fields we need to get from BvD and what represents in Salesforce. The mapping also depends on the Account data itself. So it traverses the given list of accounts, collects the corresponding mappings and returns them in a format the outer layers can understand for further processing. Accounts that don't meet any criteria (e.g. a excluded country) won't return any mapping and thus won't be updated.
The third one, the orchestrator, is the glue between the client process (requester) and the connector (data provider). So, it transforms the requests into data the connector can process based on the admins defined mappings (mapping engine) and then does the transformation back from BvD data into Salesforce data. When there isn't any mapping available, the call to BvD won't occur.
It is pretty obvious what is the toggle for in production. We need to keep the onboarding process safe from errors and be able to recover back the original flow. But it will be also useful for tests that don't necessarily have to go to the real endpoint.
The final piece in the puzzle is just the existing onboarding flow (the requester). At the moment, the only consumer is the onboarding process itself. Whenever a Sales person sends an account to onboarding, the pull of data will occur using the aforementioned layers. See more on this in the "Onboarding Integration" section.
In summary, admins will define the mapping of fields. Then whenever the onboarding process is run, the orchestrator will read the mapping and will prepare the data to then delegate the actual call to the connector. When the response is back, the orchestrator will map back the information to the account initially sent by the sales person and continue with the onboarding process.
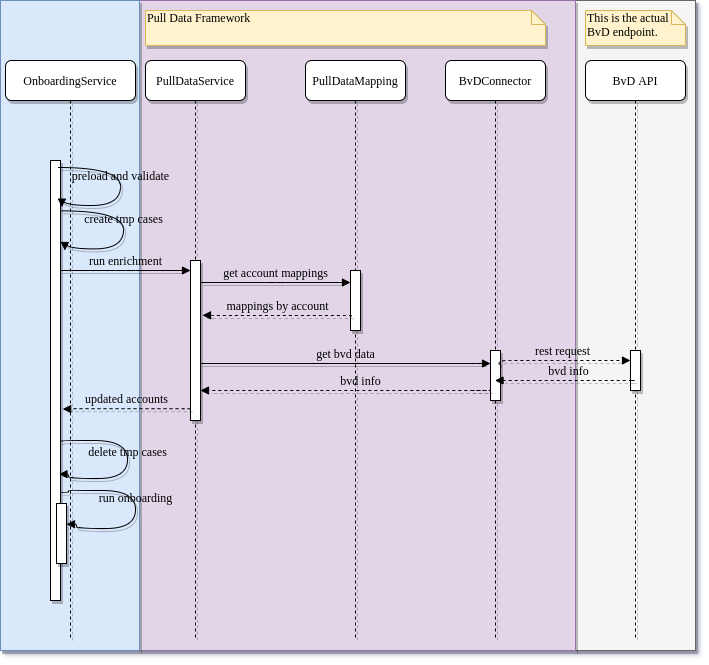
The process has been bulkified. However, the amount of data to be processed has to be accounted by the consumer depending on how heavy is the process the framework will be involved in.
Onboarding Integration
The onboarding flow is a heavyweight process not only in computational terms but also in complexity. It cares about all the possible clients (Solutions, Communities, API) but also determines whether an account can be auto-onboarded or has to be manually analyzed. This requires the logic to follow well-defined steps.
This enrichment process depends on an external service which inherently requires a callout. This is quite disruptive with the above due to the Salesforce limitation of not being able to perform callouts after DML operations. Thus the asynchronicity requirement. We cannot just plug in the call to wherever we want without dealing with an important underlying issues. How this is going to respond to users.
For the sake of this document, we'll describe the solution in the following bullet-points:
When the framework is active
- A temporary FX case will be created with a sub-status of "Enriching Data".
- Then a queueable process will be run to:
- First fetch the BvD info and update the account
- Delete the temporary case
- Run the usual onboarding activities.
When the framework is not active: 1. Run the process online as usual. No asynchronicity nor temporary case.
The different user interfaces (including the API) will be amended so that Sales and Onboarding get the same user experience. It is, Sales won't be able to run it twice and Onboarding won't see the case while it is being processed by the enrichment flow. This solution has been selected against other ones with these roles in mind, so it needs just little tweaks.
Alternatives
Before selecting the above, we have gone through an analysis of many options. Most remarkable ones are:
- Extract the logic out from Salesforce: It wouldn't solve the onboarding issue and yet will keep the connectivity concern alive. Meroever, it would require a whole new development besides a brand-new security layer just for Salesforce to connect to the VPC.
- Same framework solution but make the whole onboarding to be async without the temporary FX case. There were a couple of variations of this alternative, but although they make sense conceptually, it'd require a redesign on the whole onboarding flow. All UIs would be affected. Also, the API could be a challenge in terms of the immediacy of the data. A solution for these alternatives would require save a state in the account so that we can keep all interfaces consistent. This is far more costly.
At the moment, we will be the only ones consuming this service, so leveraging a different structure would be over engineering. There is an exception that is the Data Team. They already connect to BvD but use an ad-hoc solution built for the old SOAP API. We have discarded them as a potential consumer at the moment as it would require re-engineering from their side.
That said, it doesn’t mean the selected approach can’t be tuned to go through an alternative route via our internal secure network. What is true is that the selected approach is a better citizen of the current flow even more taking into account "auto-onboarding".
As an aside note, we realized that the Auto-Onboarding case could be replaced by a regular FX Case. There is no need of distinguishing it with a recordtype that it is even over-complicating some logic for Data Team and our end.
Caveats
- BvD doesn’t have a test environment. We chased them for that but didn't get a formal response. The dev environments we create will have to be “disconnected” from BvD to not interfere with the availability of the service. This means that e2e have to skip enrichment too.
- Salesforce doesn’t allow callouts after DML operations in the same transaction. This means that we cannot plug the “pull data update” just right after the FX case creation in the same transaction. We’d need to plug the call at the beginning of the process or do it asynchronously at the end.
Operation
This service will sit 100% in Salesforce and will form part of our internal libraries following the current SOA approach. There will be more internal consumers, but at the moment only onboarding will benefit from this.
Security Impact
BvD API doesn’t have any real authentication mechanism. They require a fixed API token to be provided in the headers of every single call. As already mentioned, there is no testing environment, so we have to be especially careful on how we share or transfer this token and do it only via the corporate tools.
There is no real harm in case of data leakage in terms of our business, but in case the token is leaked, anyone outside Ebury not only would have access to sensitive data owned by Orbis, but also could provoke a denial of service making us unable to sync data. To resolve this security concern we’ll store the token in an encrypted “Credential__c” record in the production environment and nowhere else. It won’t be in any custom metadata to avoid it ending on a repo accidentally.
Performance Impact
It was expected the pull of data and the update to be made synchronously or at least in a way that is transparent to the end users. However, we could potentially retrieve substantial amounts of data that might affect the entire transaction, even more taking into account the already busy account trigger.
As we have seen, this can't run "on-line", so will gain the vitamined limits as a side-effect of running in a queuable or batch job. It will be important to monitor the usage of the batch queue to not reach limits. The service should keep this in mind and skip the enrichment in favour of the onboarding to continue.
Developer Impact
N/A
Data Consumer Impact
This has to be developed with Onboarding Team User Experience in mind in first place. When a case gets into the onboarding queue, the pull of data should have occurred already and be transparent to them. The pull of data can’t impact their performance, so it has to be done in the less time possible. Again, it is soon to make a prediction, but it might make the flow to be adjusted to make this happen.
Deployment
Although it will occur in a later stage, the framework can’t be included into any flow without a proper contingency plan. In this case, a way to manually disable the pull of data. There will be a custom metadata type or an analog custom setting to set it up.
Dependencies
The only dependency would be the already existing connector. No other ones have been identified.