Aggregated Quantum reporting
There has been a rising demand for certain event-based (i.e. recording every single occuance of a particular event) Quantum reporting workflows but to rather to move towards aggregates of certain time periods (day, month, etc.). This Blueprint details a proposal targeting this objective.
Prerequisites
Both the problem and the solution proposed here are generic and applicable to multiple reporting flows. Yet the first candidates for aggregated reporting would be Fees Reports (both Legacy and Payment Fees). Thus the Blueprint assumes that Fees Reporting (typically: Fee Ledgers Reporting) is fully in place.
Additionally, the solution proposed in this Blueprint relies on Aggregation Services that have been already introduced within the scope of the Trade Finance Project.
Reference Documents
Accordingly, reference documents include corresponding related Blueprints.
| Reference | Document Location |
|---|---|
| EPIC01 | Aggregated Fees Reporting Project Epic |
| BPTF01 | Trade Finance Blueprint |
| BPFL02 | Fees Ledger Blueprint |
| BPE203 | Ebury 2.0 Blueprint |
Problem Description
Generally, aggregated reporting is significantly more efficient than reporting per event. Advantages include
- reduced number of database connections
- optimized data extraction
- reduced cross-services communication
- etc.
Furthermore, aggregated reports are also more beneficial from a Quantum perspective. Which is another strong reason considering to move towards this direction.
NOTE: Aggregated Reporting means aggregated amount both for credit and debit actions separately for the target. It is important to understand that aggregates are not not a single sum of all events, but a two-values pair instead: the sum of credit events and the sum of debit events.
On top of reasons above we have a "burning issue" to address -- still within the scope of Equilibrium deliverables.
Part of the current Ebury reporting, in particular reporting flows for old-style, trades-based fees are conceptually broken. Legacy fees have no tracked history, they only exist as of a current value at-the-time. Sadly, related reporting workflows heavily rely on the snapshot-like approach, making it impossible to keep an accurate track of potential fees value changes.
To illustrate the problem, let's take the following scenario. Operations Team introduces a fee associated with a particular trade (10 EUR). However, a few minutes later they realize that the value is incorrect. As of a quick fix, they set the fee value to zero, while following up the correct amount to be used. They receive a response quicker than expected -- in 5 minutes time the correct value (15 EUR) is confirmed. Operations Team now can safely set the right fee amount on the trade.
All together 3 changes happened on the trades's fee amount within 10 minutes. Assuming that the Reporting Periodic Task was executed before this scenario, two out of the three events will be completely missed. The next periodic execution will only pick up the final, correct fee value (15 EUR)... However our reporting obliations make it mandatory for us to keep track of every single change that impacted a fee amount.
Introducing any potential workaround for this issue would be pretty expensive. Therefore we rather decided to move towards hitting two birds with one stone, implementing the long-anticipated Aggregated Reporting flows.
For the example scenario above, (assuming a daily aggregate, where the described events were the only ones for the day) Aggregated Quantum Reporting would receive
- an aggregated credit amount of 10 + 15 = 25 EUR
- an (aggregated) debit amount of 10 EUR
Thus no fee-related events would be missed, while the difference expresses the correct actual amount (15 EUR).
Aggregated Reporting cancels the need for expensive rectification of current processes and data structures, as it "natively" fixes the issue. Instead of a "fixing up" existing workflows, adding "workaround" data structures, etc. old solutions can be left mostly intact and quietly dropped. Which is great, as any of these expensive "workarounds" would only provide a tactical solution, building up further Tech Debt.
Introducing Aggregated Quantum Reporting only a small, (nearly) trivial extension is needed on legacy Ebury systems (introducing notification on the events towards other, new services). As for the rest of the Aggregated Quantum Reporting solution, it offers both a strategic and a generic, re-useable response for the problem, that will be handy for the conversion of further per-event reporting flows into aggregations.
Background
History
To understand the issue we need to look back at Ebury Fees Policy evolution.
Originally fees in Ebury were applied on trades, registered as of the current fee value linked to a trade. This solution had multiple drawbacks (lacking historical track, registering no further characteristics of fees but the amount value, etc.)
Later on Payment Fees were introduced, changing the scope of Ebury fees from trade to payment. This required a whole new mechanism, allowing our experts to implement a brand-new way of handling Ebury fees. The new approach both addressed a number of issues of the old system, and added numerous new features.
Yet, old, legacy fees are still in use, and can not be "left intact" until phased out -- due to Equilibrium regulatory requirements.
Challenges
Before going forward, we should take a moment to reflect on the challenges of Aggregated Reporting as a task.
Aggregating any data (that's not been reported on individually) means "alternation" between actual and reported events. Even though those events may not count today, we can't just "let them go". Audit requirements towards Ebury strictly require that all events must be registered and possible to re-visit if needed back in time.
Assume that any generated aggregations contained programmatic errors: if the original events are lost, there is no way to rectify data that was reported by mistake.
Therefore any non-stricly-event-based reporting mechanism has to consider a list of strict requirements making sure that it fully complies to all legal and audit requirements that the company has to correspond to.
This typically has an impact on data being stored, logging, etc. While overly considerate, still to be smooth, optimized, efficient and asyncronous.
Solution
As already hinted, we propose a strategic solution for the problem.
Data aggregation (for reporting) is the type of problem that's worth addressing separately, on its own. Partially because of the complexity of the issue, partially because it's a generic problem. Any data aggregation attempt will have to comply to the same set of requirements (traceability, audit trail, no data loss, etc.)
Providing a new, generic solution, we should certainly do it within the scope of Ebury 2.0, as an asyncronous service, part of a distributed system.
Especially since components of this chained workflow are already available, dedicated to the purpose that's also needed by this project. Their functionality may not yet fully cover our needs, however straightforward extensions enable us to re-use the already existing frame, that is targeting the same overall purpose. Thanks to previous projects (like Trade Finance), the Quantum Gateway service is already available, together with a Data Aggregation Service.
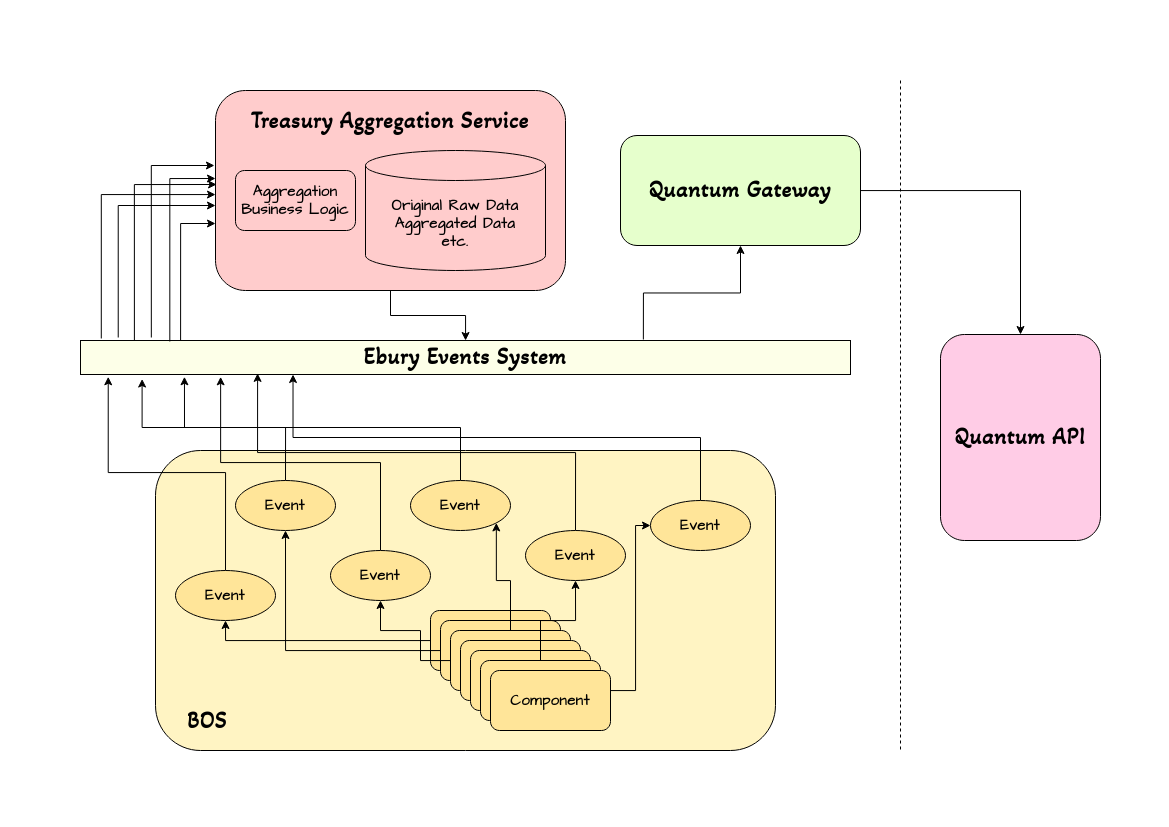
As demonstrated on the diagram, this solution reduces modifications to be added to the legacy Ebury systems. The only missing step on the actual legacy code is to communicate the set of events concerned to the Ebury Events System (Kafka bus). The set of events is very well-defined and small for the use cases addressed within the scope of this Blueprint: Fee creation and update. Luckily we have well-establised tools for this task, and given the simplicity of the information in question, the message format (i.e. data communicated) will be pretty straightforward to define as well.
The Aggregation Service has to subscribe to notifications coming from these events. It has to provide full traceability, from the raw data to the aggregations published for further usage. Responsibilities of the service are to
- store the data received, so there is NO data loss
- apply aggregation calculations whenever needed (end of the day, etc.)
- save aggregated data that will be publised for Quantum
- publish aggregated data to the Ebury Events System
- ensure adequate logging.
While some of this functionality is already available, a Business Logic extension (and a periodic task) will be still needed to calculate the fee aggregates once a day.
As a next step, the Quantum Gateway has to consume the aggregated data from the Ebury Events System, and publish it to the Quantum API. Here again a small extension is to be added (handling the custom input Quantum API call), yet it's pretty straightforward to insert the new pattern to the existing frame.
Alternatives
A tactical solution could address part of the problem (for example, typically the "burning issue" of missing history for Legacy Fees). However, one one hand this solution would be significantly more limited, addressing a single specific broken behavior instead of a re-usable generic solution. On the other hand, an extension workaround to the current legacy systems would be much elaborate (both on a code and on a data level). It's simply not worth the investment for a "throwaway" solution, when the same amount of effort could deliver a re-usable, generic, extendible solution within the scope of asyncronous (micro)services.
Caveats
None foreseen. Aiming for straightforward extensions on existing services, acts on our behalf, as no conceptually new solution is to be set up. As always, particularly careful planning is needed for any new data schemas (including event messages definition).
Operation
The workflows described here would receive their input whenever an event in question may occur, anytime during the day. Then the Aggregation Service may act as a "buffer", permanently storing all this data, while only generating aggregates output at specific times using periodic tasks. Aggregated data would then be delivered to Quantum Reporting Services.
Security Impact
None foreseen. (Note that access to external services (Quantum API) have already been safely ensured).
Performance Impact
Anyncronous, offline aggregates generation has multiple advantages, starting from reduced data access to reduced amount of inter-services communications. Assuming optimized workflows in terms of execution together with data storage and consumption, this solution should be a significant performance improvement compared to the current, per-event reporting.
Developer Impact
More Quantum Reporting functionality outside of legacy systems. More strategic, long-term solutions.
Data Contracts
Data contracts require a particular attention in terms of
- the new Event messages definitions
- Aggregation Services Data Storages
However given the simple nature of the data concerned, both should be straightforward.
Data Sources
Input data: BOS events (Fee creation and update)
Transformation: Separate summary of credit (added) and debit (deducted) amounts applied on a Fee value.
Output: Aggregated data published to Quantum API
Deployment
Changes should be implemented as seamleess extensions of existing services. They could be rolled out independently, however the full chain should be tested before enabled in Production. Feature flags are recommended to be used.