Runbooks
The goal of this RFC is to propose a process for creating monitoring plans for the teams in charge of supporting our applications (from now on, the support teams, and currently being Tech Support, SRE and Business Apps) containing runbooks for all alerts and issues that must be handled by the teams. This way, everything the team needs to mitigate an incident is in one place, following the same structure and properly maintained.
Problem Description
Currently, the monitoring plans that Support and SRE use for working on alerts and incidents are spread across different Google Docs with different formats and lacking relevant information in some cases. In addition, these documents are not properly maintained, which can cause issues when trying to mitigate incidents; this problem is even bigger outside working hours when the pertinent development teams are not available.
Background
Currently, there isn't a common way for the teams to work on the monitoring plan for the projects they work on.
Some teams work on the alerting and monitoring throughout the development process of the project, some others don't include monitoring-related tasks until the very end of the project. When in this last scenario, it is usual that the monitoring plan is lacking information and does not meet the necessary requirements for the support teams, and therefore the project roll-out phase is blocked. This is something we always want to avoid.
An additional problem we face with the monitoring plans is the format. Each team uses a different format and includes different information. The result is that the monitoring plans are spread across different documents in different locations; when an alert raises, it can be difficult to locate the specific document where the corresponding monitoring plan is written.
The last problem we currently have is ownership and maintenance. Because the team composition changes from time to time, some alerts, specially the older ones, don't have a clear owner, and because they don't have an owner, they are not maintained. Trying to mitigate an incident with a deprecated plan could be dangerous as we could be generating inconsistencies in the database, losing information or causing errors in other processes.
Solution
The proposed solution is to use a GitHub repository for creating, organising and maintaining the runbooks, and GitHub pages for exposing them.
Page Structure
The home page will hold an index with all the runbooks organised based on services and service owners. Each runbook will be identified by the name of the alert they relate to. This will make it easier for the support teams to find the runbooks related to the alerts raising. The structure will look like the following:
- SERVICE OWNER 1
---- SERVICE 1
-------- alert 1
---- SERVICE 2
-------- alert 1
-------- alert 2
-------- alert 3
- SERVICE OWNER 2
---- SERVICE 1
-------- alert 1
-------- alert 2
Each alert above will be a link to the corresponding runbook
Runbook template
The runbooks must follow the below template:
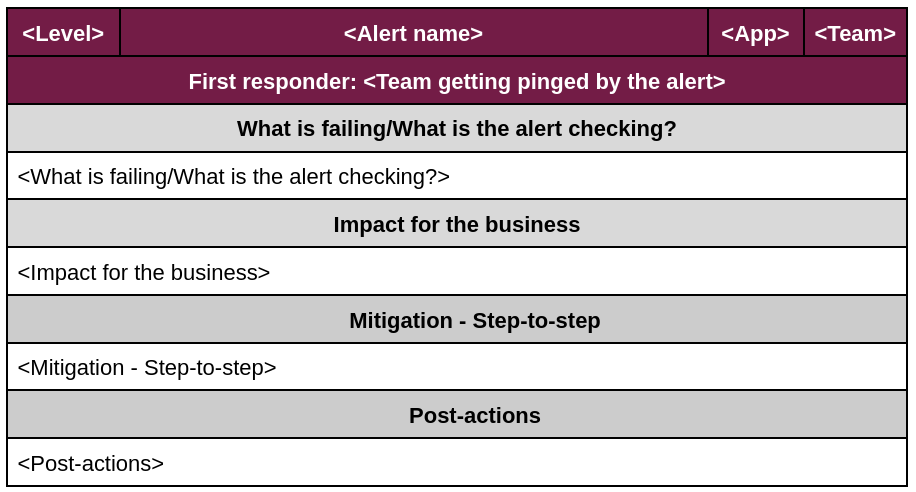
A template file will be added to the GitHub repository for convenience; it must be filled up as follows:
- Level. Level of criticality of the alert (Critical/Warning). Critical alerts will send an alert to Splunk (commonly known as VictorOps) and therefore will notify the team even outside working hours. A warning will not notify the team, but will appear in Nagios/Alert Manager.
- Alert name. Name of the alert that the team will receive in Splunk or Nagios/Alert Manager, so it is easily identified.
- App. Application the alert corresponds to (BOS, FXS, Sherlock, etc.)
- Team. Development team responsible for maintaining the alert.
- First responder. Team receiving the alert (SPP/SRE/BPA...)
- What is failing/What is the alert checking?. Summary of what the alert is checking and why it is raising.
- Impact for the business. Brief explanation of the business impact that Ebury will suffer if the alert raises, so the team can properly evaluate and escalate an incident if needed. You may refer to the Critical Operation table.
- Mitigation - Step-to-step. Clear step-to-step guide on how to solve the problem related to the alert. To be considered:
- If Kibana/Grafana is to be checked, the corresponding view is to be linked.
- If specific information needs to be checked, it is necessary to include links to the relevant applications or the specific queries that need to be run to get said information.
- Ebury is working 24 hours a day; we need to avoid adding actions like contacting a certain development team as they might not be available when the alert raises. That can be added as a post-action, but it shouldn’t be part of the mitigation step-to-step.
- Post-actions. Any action required after the alert is resolved such as contacting the stakeholders via email. If needed, include the team group email, or the particular Head of Team.
Maintenance of the runbooks
Regular maintenance
The service owners are responsible for maintaining the runbooks; the owners will be easily identifiable as their name must appear in the top right corner of each runbook and in the index in the home page. They must ensure that the runbooks:
- Have the right criticality level
- Have the right team ownership
- Have its step-to-step correct and up-to-date
In order to have information regarding when the runbook last reviewed, the runbook metadata will contain a "last reviewed on" date field (it will be included in the template as well). This way, the owners of the runbooks should create a pull request updating the review date so the runbook can be considered as officially reviewed.
Change of ownership
If a team owning a set of alerts disappears for any reason, a new owner must be assigned following the Service Ownership process. The newly assigned team to the alerts will then be responsible for revising and confirming that the alerts are up-to-date.
Alternatives
Initially it was proposed to collect the Runbooks in a single Google Drive, but that approach has some problems:
- Contributing. We want to allow developers to contribute by adding new Runbooks, but we also want to make sure the new Runbooks are reviewed and approved by Support, SRE and/or Business Apps before they are published. Implementing this behaviour in a Google Doc is not straightforward, as we would need to grant full permissions to support teams but only suggesting permissions to the rest of the teams; this can't be achieved if the document is in a Tech Shared Drive, as everyone has full permissions. Creating the document in a personal-private drive is not ideal, and granting permissions to new joiners one by one is not scalable.
- Performance. It is to be expected that the number of Runbooks keeps growing; having a Google Doc with hundreds of pages is not feasible as the loading time and the versioning tool's performance can be severely affected.
- Traceability. Pull requests are easily traceable and can be linked to a Jira task; changes in a Google Drive can't.
Caveats
This process heavily relies on the owners' due diligence; if the alerts are not properly reviewed and maintained the runbooks won't be useful.
It also relies on the teams setting proper monitoring in place: if errors or unexpected scenarios are not managed and raised as alerts, we could be missing severe problems in the platform that might lead to incidents. In this RFC we are defining the process of creating and maintaining runbooks, but what to monitor and what alerts to raise falls out of the scope of this document.
Operation
The repository and corresponding GitHub pages site will be managed by the Support team.
Each service owner must be responsible for adding their runbooks following the process described in this RFC. They must take into consideration that the support teams will need some time to review the runbooks; ideally, that time should be 2 weeks in order not to affect the tasks in the current iteration.
The service owners must be responsible for maintaining their runbooks.
Security Impact
No security impact; the runbooks must not contain sensitive information. If the support teams need access to a certain application, the credentials must be provided using the appropriate channels, under no circumstances they must be written in the runbooks.
Developer Impact
Development teams must have this process into consideration when designing solutions, as applications without the corresponding runbooks won't be supported.
Setting proper monitoring in place for new applications is essential to guarantee the availability of our system and the continuity of our business, and therefore it is an important part of the development process of new projects.
Improvements and future iterations
Ideally, we should have a process that prevents a new application/service, or an upgrade to existing, from being deployed unless a runbook has been reviewed and approved (or confirmed with the teams that a runbook is not necessary). More specifically, we would need a process that ensures that:
- Runbooks are easy to find by alert name but at the same time they live within the same repository of the application/service they relate to.
- All the repositories follow the same directory structure for storing the runbooks.
- Although the runbooks would be in different repositories, they will all be build and centralised to a single place.
- The existence of approved runbooks (or the justification for not having them) is a mandatory requirement for deploying services into production or for updating existing ones.
- The centralised site has a searching functionality.
All these requirements are considered to be out of the scope of this RFC, but they will be taken into consideration for future iterations.