Event -Driven Architecture Patterns
Problem Description
There are a variety of architectural patterns designed to support an event-driven architecture, and in order to ensure implementation success, a consistent and shared approach to event asynchronous event-driven architecture is required.
Background
Ebury technology architecture has expanded in size and complexity over many years. The evolution of its systems have centered around a few key custom applications that have become difficult to adapt to rapidly changing business needs and increasingly complex to maintain.
The Ebury 2.0 blueprint documents the business drivers in detail and concludes a decoupled, secure and robust architecture, based on event-driven design, will deliver the technical agility required to meet business needs.
The use cases associated with the current phase of Ebury 2.0 are mainly associated with the strangler pattern – gradual migration of functionality from a monolith system to a target e.g., beneficiaries. The primary pattern identified to achieve BOS decomposition is the ‘Change Data Capture’ pattern (described in this document).
Solution
Document patterns that support an asynchronous event-driven architecture with guidance on the benefits and drawbacks of each – to be discussed and agreed with engineering teams.
This document will continue to expand with new patterns added as appropriate.
Change Data Capture (CDC) Pattern
Change data Capture ensures database changes are observed and extracted as change events and replicated to a target data store. Effectively CDC treats a database (the DB that changes are captured) as a leader and downstream data stores as followers – log based message queues are well suited to transporting the change events.
CDC is commonly implemented when data changes occurring in a database are required to be replicated to another database or reacted to by down stream systems/services and it’s impractical to capture/divert a data change at the perimeter of a system or by amending the underlying application code.
In the context of a migration, CDC is commonly applied when deconstructing a monolith application to support other strategies such as when applying a strangler pattern. Separately, CDC is used to replicate data for a multitude of reasons – resilience, materialised views etc.
Although a useful pattern, the use of this pattern should be minimised and must be recognised as a transition step only and not the end goal, because it does encourage coupling to the internal data model and each of its implementations do present challenges.
The following are some implementation approaches of CDC:
Change Data Capture - Log based
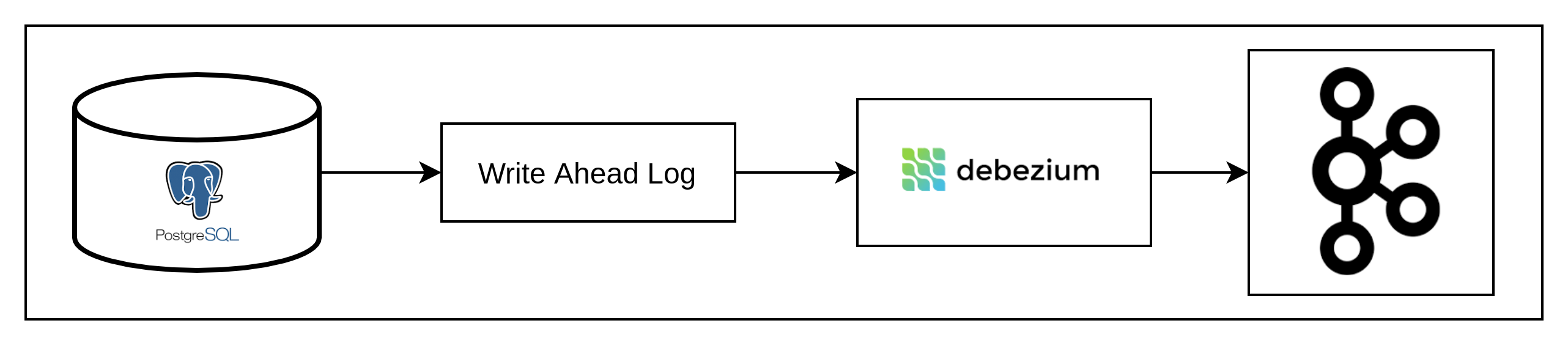
Database changes are written to an append only log ready for extraction into change events – the implementation varies between platforms e.g., PostgreSQL changes are extracted via the WAL log, whereas MongoDB offers an event stream interface.
A common implementation approach is to utilise a ready made connector (available to some DB’s), an example below (fig. 1)
Write-Ahead-Log fig. 1
Positives
-
All changes are captured: Create, Update and delete (this isn’t true of all CDC implementations)
-
Minimal impact of data store performance
-
Updates can be propagated to a destination from source immediately which results in relatively low latency replication.
Negatives
-
Careful consideration is required when managing access to the underlying data model, given that all changes are exposed in the change log – can be a considerable overhead for data engineering teams.
-
Change logs contain all changes (Change events) and therefore by and large normalisation is often left to the downstream services – impacts performance and potentially risks data integrity.
-
Tight coupling of the data source schema to events – a change to a source DB schema could break downstream event consumers.
-
Depending on the use case, asynchronous data replication requires careful consideration (see CQRS pattern for ‘read your own writes’ & Kafka standards for data guarantees)
Change Data Capture – Query
This pattern is fairly simple, it involves querying a database for specific data and then submitting the results to a destination e.g.,data stream.
Positives
-
Totally customisable – select the data that is required and the schedule at which the database should be polled.
-
Given the data query is customised it means the output can be isolated from the data model thus keeping the domain model private to avoid data misinterpretations and tight coupling by downstream teams.
Negatives
-
Understanding which data has changed since the previous query
-
Deleted data isn’t marked as removed and are not traceable.
-
Timestamps must be available for tracking and to include in the event-driven
-
Query sizes may vary that could introduce lag that impact race conditions and also the database performance could be impacted
-
Tight coupling of the data source schema to events – a change to a source DB schema could break downstream event consumers.
-
Depending on the use case, asynchronous data replication requires careful consideration (see CQRS pattern for ‘read your own writes’ & Kafka standards for data guarantees)
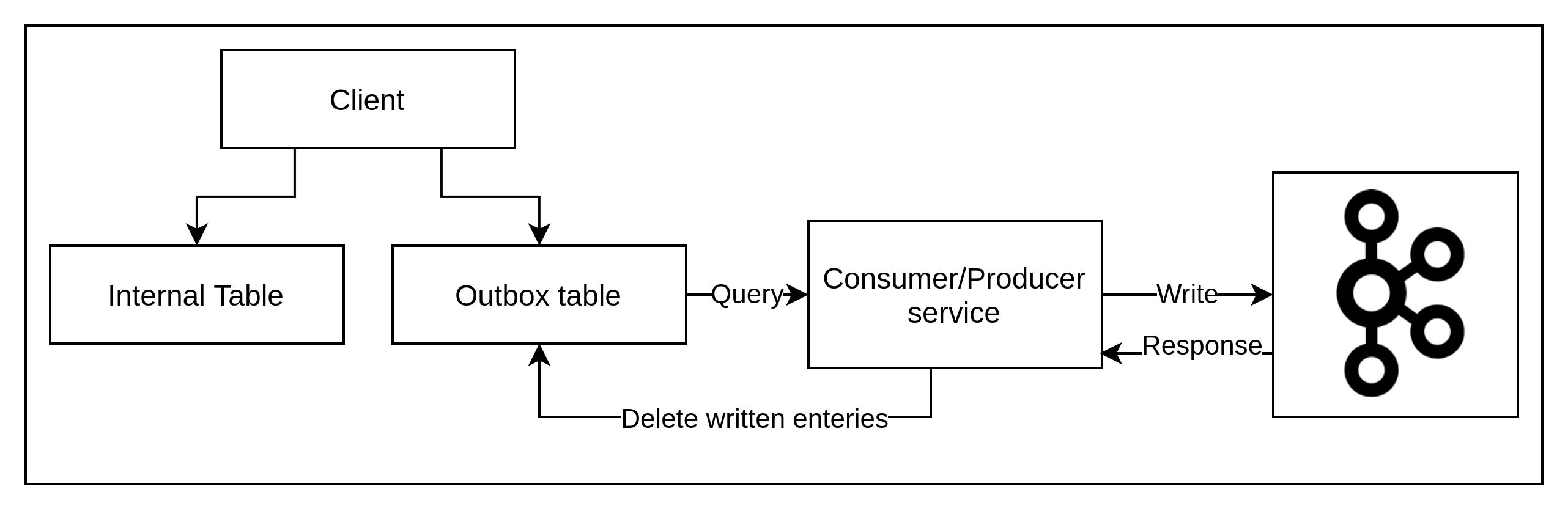
Change Data Capture – Outbox tables
An outbox table is implemented to capture a copy of specific changes that occur within a database. When a change occurs to a database table monitored for change: insert, update or delete action the action is mirrored in the corresponding Outbox table (updates to both tables, must be an atomic transaction – serializing prior to the commit is preferable).
Positives
-
Given the data selection is customised the output can be isolated from the data model thus keeping the domain model private to avoid data misinterpretations and tight coupling by downstream teams.
-
Data can be denormalised prior to being written to the outbox table.
-
Schema can be validated as part of an atomic transaction i.e., prior to committing to a change to the outbox table.
Negatives
-
To enable the outbox pattern code changes are required – this may not be viable due to resource, cost, knowledge and timescale constraints
-
Small changes may not cause a noticeable impact, however, large implementations will impact performance and could impact business process – SLAs etc.
-
Depending on the use case, asynchronous data replication requires careful consideration (see CQRS pattern for ‘read your own writes’ & Kafka standards for data guarantees)
Event Sourcing
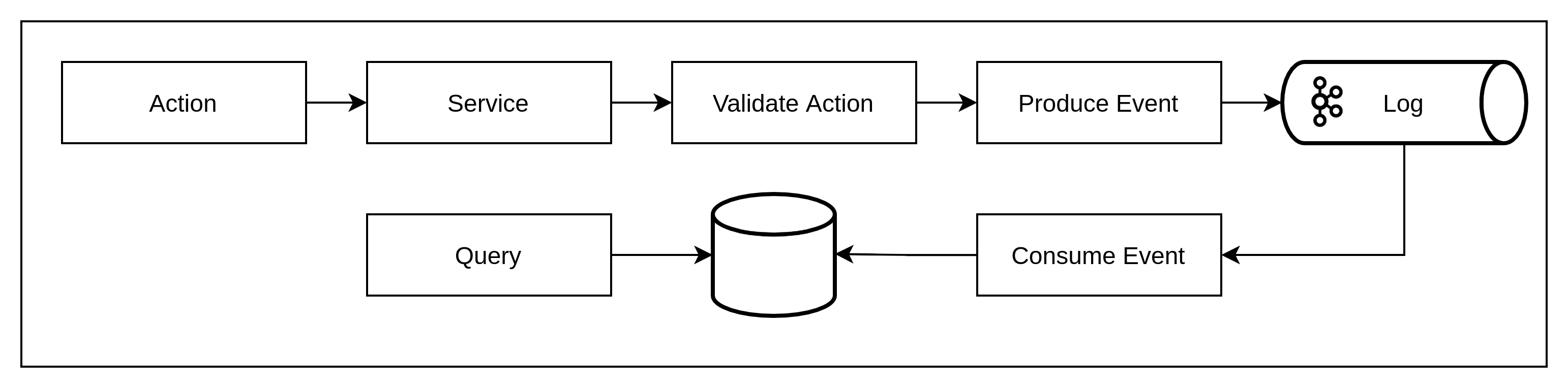
Event sourcing is a technique of journaling application events to an immutable log – the application logic is specifically built to create events that represent changes that have happened at the application level. It’s more meaningful to record events at the application level than at the abstracted level of a database because context can be provided e.g., ‘Payment Paused – PEPs flag’ is more meaningful than two separate DB entries of a payment status and a PEPS flag
Although a very powerful technique for data modeling from an application point of view, and enables performance, auditing, and resilience benefits there are overheads to consider; a change in engineering approach e.g., domain driven, new technologies, management of services and new design concepts.
Benefits
-
Derive current state from a log – because the history of changes is maintained in the event broker append log, event data can be replayed from the beginning of the log to any point in time point in time that is recorded in the log...time machine!
-
Derive several views from the same event log – for example, an event log that contains account opening events could be used to notify customers, real-time analytic dashboards or replicate data to several different data store views/cache etc.
-
Performance and resilience benefits gained by utilizing an asynchronous integration model
-
Provides detailed insight in to user and system behavior – powerful for troubleshooting and customer insights (particularly when command and event sourcing are implemented together).
Drawbacks
-
Depending on the use case, asynchronous data replication requires careful consideration (see CQRS pattern for ‘read your own writes’ & Kafka standards for data guarantees)
-
It is possible to obfuscate data in an immutable log… however, there is a huge reliance upon data governance and integrity given the vast amounts of data that is stored in an event broker, without controls there could be no guarantee all data is cleared.
Command Sourcing
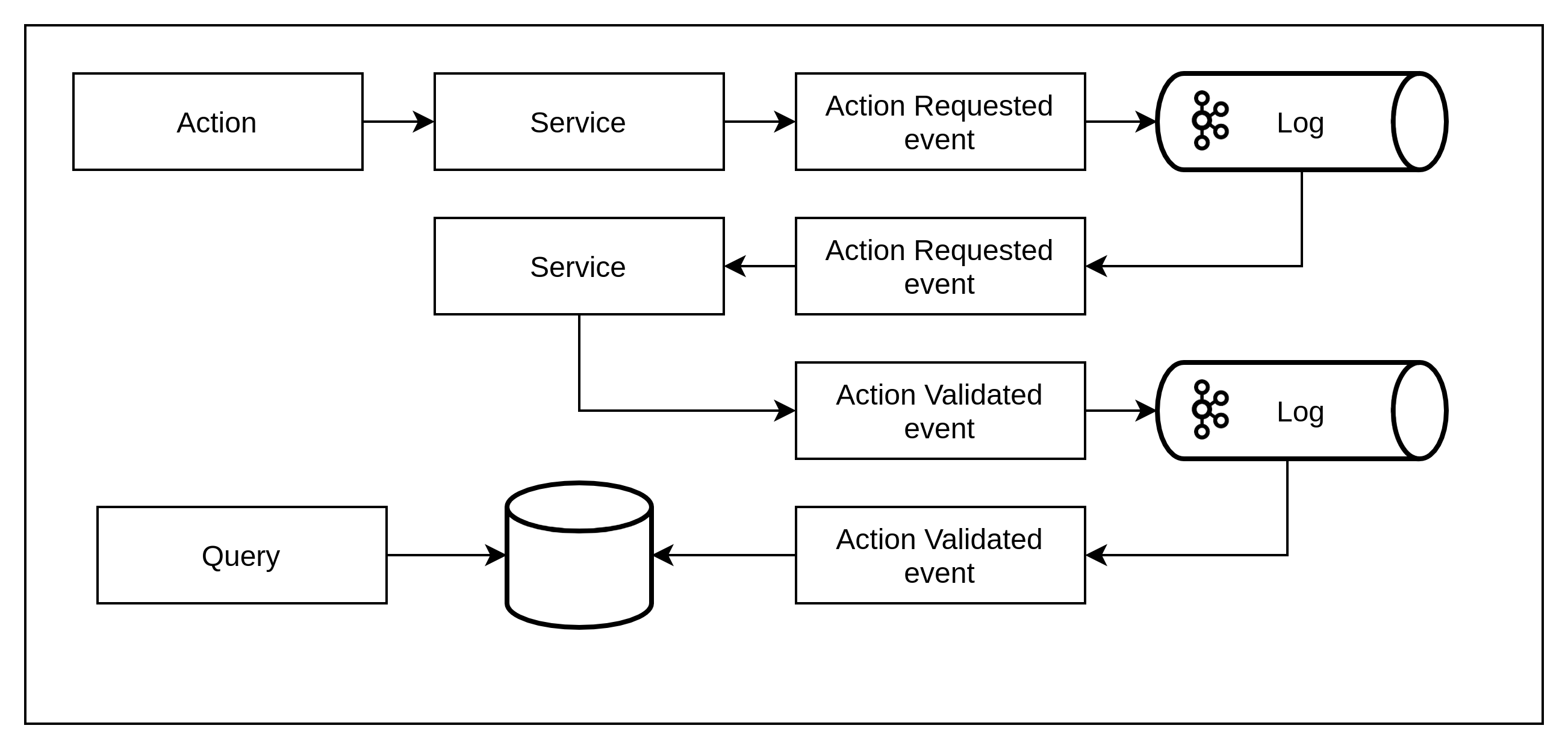
Command sourcing is similar in concept to event sourcing but begins with a command – in other words, a command event contains the intent of an action (equivalent to a RPC request).
As depicted in figure xx, a request is made by a command service that generates a command event – this command event is now immutable, the command event will be processed and the result returned as a domain event.
Benefits
-
Provides detailed insight in to user and system behavior – powerful for troubleshooting and customer insights, (particularly when command and event sourcing are implemented together).
-
Version controlled - if a critical bug is discovered, commands could be replayed, once the bug is fixed, to recreate state minus the bug.
-
Performance and resilience benefits gained by utilizing an asynchronous integration model
Drawbacks
-
Depending on the use case, asynchronous data replication requires careful consideration (see CQRS pattern for ‘read your own writes’ & Kafka standards for data guarantees)
-
It is possible to obfuscate data in an immutable blog… however, there is a huge reliance upon data governance and integrity given the vast amounts of data that is stored in an event broker, without controls there could be no guaranteed all data is cleared.
-
Inevitably additional services are required to support the command pattern – the service proliferation will require management – it’s manageable, but only with a controlled approach such as an engineered focused workflow engine (Temporal has been discussed as an option).
Command Query Responsibility Segregation (CQRS)
Maintaining a single read and write model is a common and traditional approach to storing data in a database. However, if storing data could be accomplished without having to be concerned with how it will be queried and accessed then the approach could be simplified.
In essence the CQRS pattern separates a command service from a query service so that write commands can be written to a separate database to that used for queries – data is replicated between stores to keep each model in sync. How data is moved between data stores can vary depending on the implementation.
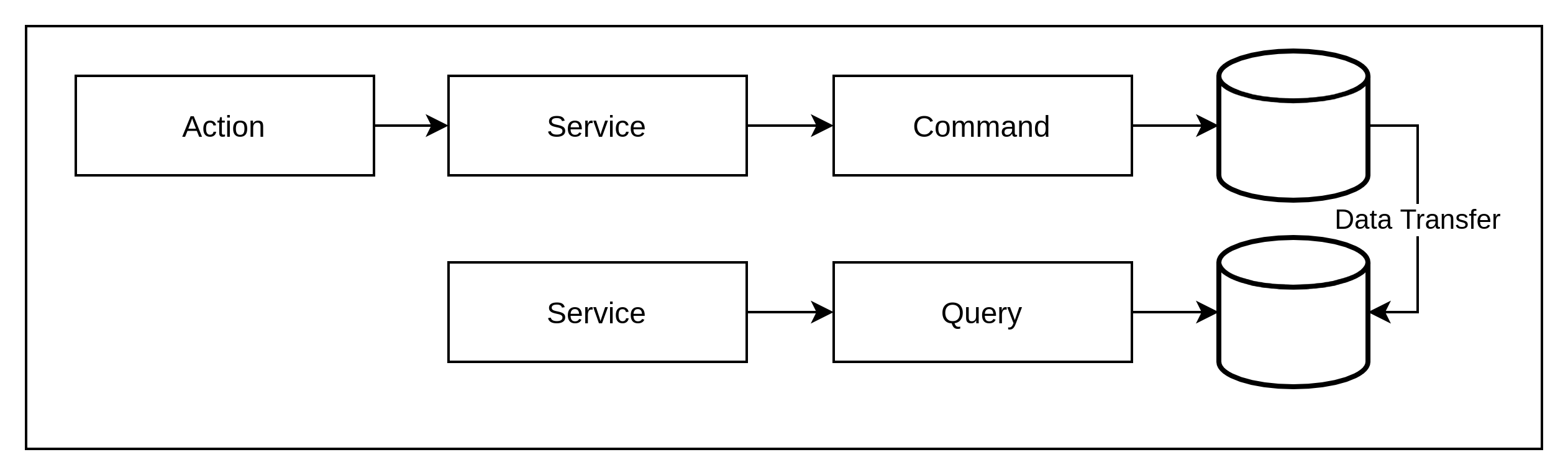
CQRS + Event Sourcing
When Event-Sourcing is implemented with CQRS – as it almost always is, the flexibility of the derived views that can be created (with event streaming), is considerable when compared with change events (database level – coupled to the data model of a DB). Moreover, a single event can be consumed independently many times in parallel to reduce lag when replicating data views to different data stores.
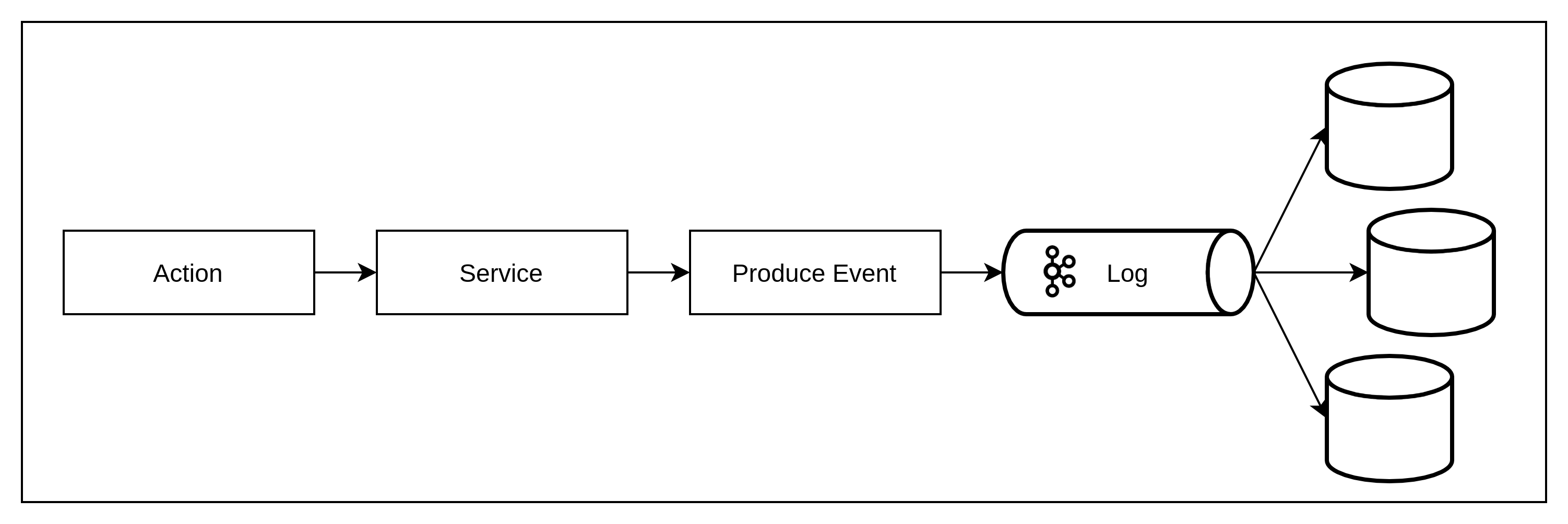
Benefits
-
Splitting write and query models enables optimized views to be created (Polyglot storage/views)
-
Supports the separation of concerns principle
-
More easily manage data views to be shared (queried) by other services – supporting the ‘keep data on the inside private’ approach to microservice implementations
-
-
Additional performance & flexibility benefits when implemented with event sourcing rather than database level events
Drawbacks
-
Complexity to implement and operate – additional services are required for the command/read structure.
-
Eventual consistency between write and read data stores is a challenge to be considered with CQRS. Some use cases may cope with some lag between a write and a read from a derived data view, however, others may not be so forgiving e.g., credit a bank account and immediately read the balance – an accurate balance must be available. The approach to ‘reading your own writes’ will differ depending on the specific use case e.g.,
-
Implement ‘blocking’ (long polling – other methods are available) to make an asynchronous operation appear to be synchronous.
-
Another option could be to write to the read data store and event broker at the same time using an atomic transaction or distributed transaction depending on the circumstances.
-
Event Collaboration Pattern
Event collaboration describes a series of independent and event driven services that work together to form a business process (workflow). This pattern enables the autonomy of each service in the workflow by utilizing a series of events to trigger an action asynchronously rather than each service synchronously calling another. The diagram below depicts a simplified event collaboration example.
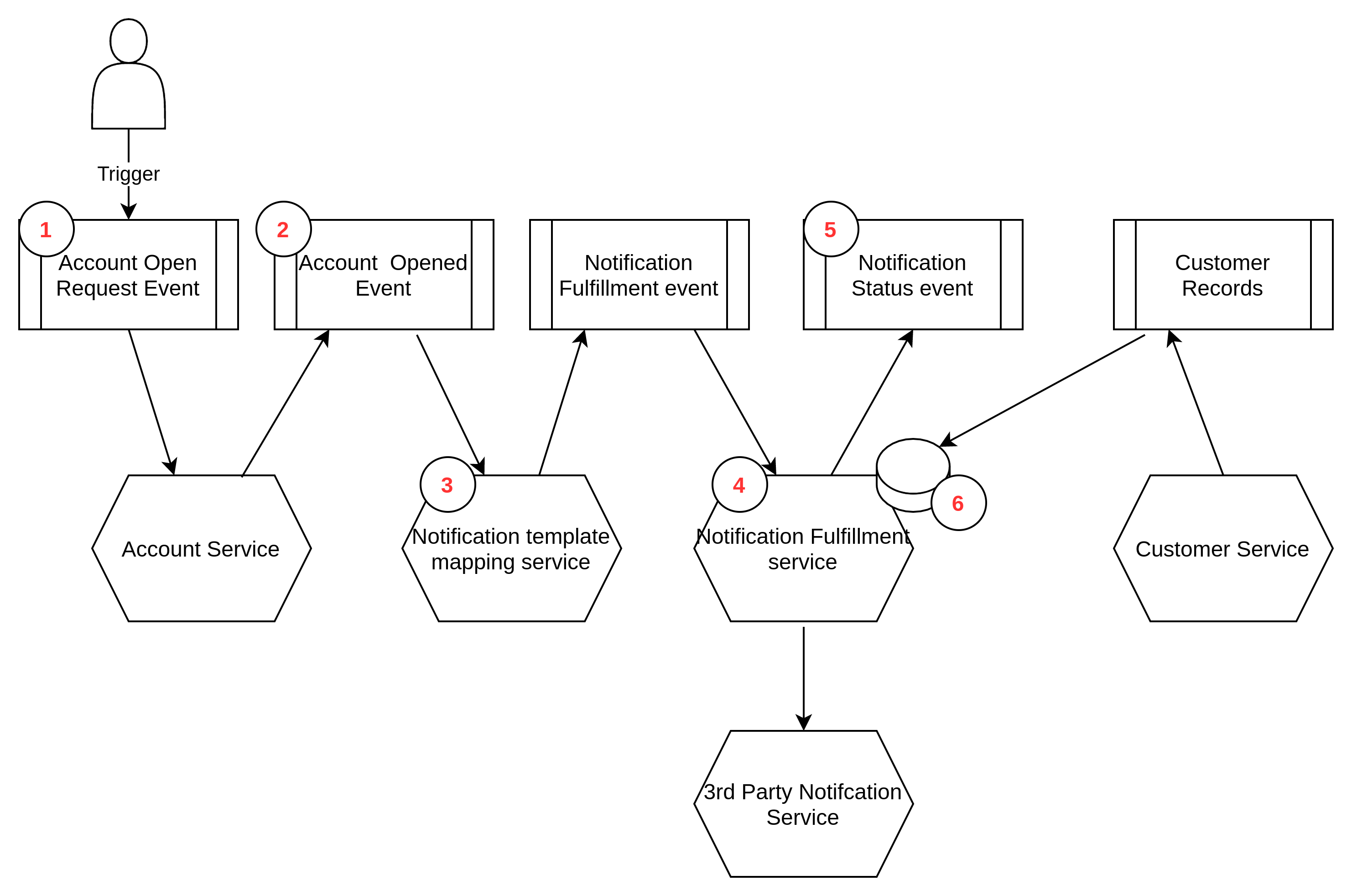
1 - User triggers an account opening request 2 - The account is opened and an event is generated 3 - A notification template service reads the account opened event, maps the account details to a text message template, and produces an event with the relevant fulfillment details – the text message details could be in the event or a separate data store (this is implementation detail). 4 - The notification fulfillment service reads the event, looks up the contact details associated with the account & posts the information to a 3rd party text message service (synchronously) via an API. 5 - A successful response from the 3rd party notification service is converted to an event. 6 - The Notification fulfillment service could make a call to the ‘customer service’ for customer contact details that are required to send a text message – however, in this example the customer details are replicated to a local data store that contains account number and associated telephone number (State transfer)
Benefits
-
Performance and resilience benefits gained by utilizing an asynchronous integration model
-
Event driven services enable change more easily because of their decoupled architecture, e.g., if the account open event were to be used to create a reminder to a customer to fund their account, this could be done without impact to the account service.
Drawbacks
- ‘Event sprawl’ can occur as the volume of event driven services increase. The advantage of decoupling could also lead to an opaque view of what each service is responsible for. There are strategies for this which include managing what is a long lived process in code – workflow engines (Temporal.io has been discussed as a possible candidate).
Event State Transfer
Essentially the event state transfer replicates data when a change occurs to ensure replica data sets are kept recent (CDC is a form of event state transfer). The pattern could be implemented with Kafka sink connectors or bespoke consumers that detect new events and replicate to a data store – additionally data streaming can be applied to merge data streams to derive data views. Step 6 in the ‘Event Collaboration’ pattern is an example of event state transfer.
Benefits
-
Improves team autonomy by sharing data but not relinquishing control (the event stream is managed by the owning service)
-
Improved performance by providing a local copy of data to a service or system etc.
-
Enables offline data access e.g., if an owning service is unavailable the local copy could be used (depending on the use case).
Drawbacks
-
Replicating data will naturally add complexity because operationally there is more to manage.
-
As mentioned in the CQRS pattern, asynchronous replication introduces the possibility of data lag – if a use case required the write to be read immediately there will be additional considerations.