BOS Data Migration FP <> Core
Unify BOS data on a common database
Problem Description
The main problem we need to have in mind is that we have 2 different BOS environments running for different companies duplicating our infrastructure, releases, settings, configurations, etc.
Background
In order to unify BOS for FP and Ebury environments, we need a program of work to follow and with the proper steps to achieve it.
FP became part of Ebury, and it should work as a brand under the Ebury environment.
FP environments have a lot of data, so we need to have in mind how to migrate that amount of data in the best way possible taking into account the risk to migrate that data and validate it.
Solution
The solution is to incrementally deliver data over a series of epics to the core platform. This will allow data to be pushed in batches but also validated and, in some circumstances, configured, over the course of the delivery. The migration will involve one way synchronisation from FP to the core platform that will continue for the duration of the migration programme of work.
Initially clients will be migrated, and the brands related to FP hidden from view to avoid any attempt to interact operationally with them. This should be extended to cover all processing of data so that these brands are not part of the day to day working whilst the migration project is ongoing. On successful completion of the synchronisation of a domain of data (clients, beneficiaries, deals, payments, etc) between FP and core, the data can be validated regularly to ensure consistency between the platforms whilst other domains are migrated.
As synchronisation will be ongoing, at the point all data domains have working sync processes, if access to FP was stopped the data state from FP to core would have been replicated. Subject to the application and services being fully tested users could then access enabled FP brands on the core platform.
The reasoning behind choosing this as an option is it allows the project to be broken down into a series of deliverables each with their own requirements and validation rules. It also avoids the risks associated with a single large migration script and subsequent large reconciliation. Data can be reconciled in small batches and by data domain which will also provide confidence in the process and highlight issues much earlier in the delivery.
Synchronisation has its disadvantages as there will be an increased overhead on delivery but on balance this is felt worthwhile to mitigate the risk of a ‘big bang’ approach.
The process for pushing data from FP to core can be broken down into 4 distinct stages;
- Extraction - pulling the data from the data source.
- Validation - pre-processing prior to the data being loaded into the target core database.
- Synchronisation - data is loaded into the target code database.
- Acknowledgement - confirmation that data has been loaded into the target core database.
Data will be sourced from two areas, FP and Salesforce.
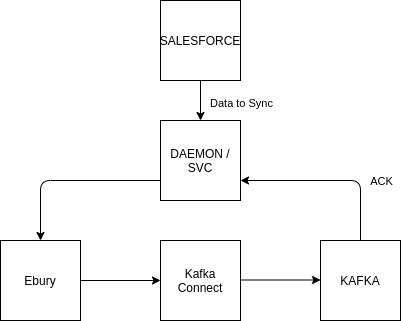
SF already has existing flows through to core. Core -> SF API using our Salesforce synchronization process already developed, receiving only information from FP brands in order to populate the information in BOS without any collision with primary keys.
For data coming directly from FP we will use the Postgresql -> Kafka Connect (Debezium source connector) -> Kafka with the retention period set to infinite to retain the data for as long as necessary during the migration.
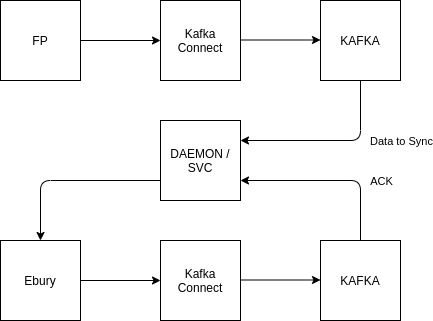
Key to the order in which the data domains are synchronised will be their relationships to ensure consistency when the data lands in the core BOS platform. For example we cannot push a beneficiary into the database without its related client and so on. To ensure this data consistency is maintained through the migration a component will manage the data load into the target database by performing the validation (is the client available for the beneficiary I need to load?), synchronisation and acknowledgment (beneficiary X was successfully loaded).
The acknowledgement flow will also be handled using Kafka Connect as each table that data is loaded into can then emit an event to a topic that the synchronisation component can subscribe to. This will also have the benefit of supplying any new primary keys generated at load time to the synchronisation component for use in loading other data elements.
Delivery
Delivery will be across a number of teams and will involve an RFC per epic to ensure the data domains validation and synchronisation processes are agreed.
This list is not an exhaustive set of epics that will be delivered but provides an indication of the structure of delivery. Some of these work streams may be started in parallel.
Preparation:
- Epic 1: Test environment setup
- Epic 2: Kafka Connect extract of FP data
- Epic 3: PoC and subsequent design on how to exclude particular brands from the core BOS platform processes.
Domain Synchronisation:
- Epic 4a - 4n: Domain data synchronisation epics (e.g. client, beneficiary, deal, etc.).
- Epic 5a - 5n: Service / application configuration changes to support FP and core on the same platform.
Additional Work:
- Epic 6a - 6n: Other systems / data stores to be merged (e.g. FX Suite) if necessary.
Alternatives
-
Have a new database and stream all the changes from Ebury and Frontier databases to that database using Amazon Kinesis. pros about this alternative is that the synchronization process can be automatized faster and using AWS tools, the cons here is that we can not synchronize elasticsearch or audit, so only with this solution can not cover all the cases we want to cover.
-
Keep both database but add a Router in the application and choose one database or other depending on the brand of the related user of the request and add in all periodic task a brand option to choose the FP database, by default is going to go to Ebury database as usual. This solution has its own pros and cons; A pro is that we avoid to a data migration and go directly to the next step of the FP migration. Some cons are we are just delaying the database migration because at the end we want just one database and with this solution we need to keep 2 databases, 2 queries databases, 2 Elasticsearch and 2 audit databases.
-
Run a huge data migration with all the information from FrontierPay to Ebury in a weekend and FP Team can start working on the Ebury environment. This solution is too risky to take into consideration, we won't be able to check if all the data is going to be created without any problem.
Caveats
Obfuscate the FP database for the staging environment to have real data to work with.
Some primary keys are going to be updated to new one due to collisions, this is going to change some references from Deals, Payments and Clients, also the uuid generated by UUIDModelMixin is going to change to because is generating the identifier based on the primary key on the instance.
Only reconciled data from FP is going to be created in core environment. Data reconciled from FP means, data that we can relate to a FP brand.
All the information from FP is going to be exposed in Ebury environment, so we need to think if we want expose them to Quantum or in the reports.
Operation
Operation team is going to see all the information from FP, this is not a real problem, but this can lead to a misleading from their side.
Security Impact
FP users can see/do actions over Ebury deals, payments, clients...
Ebury users can see/do actions over FP deals, payments, clients...
Permissions and Groups are going to be shared between users of Ebury and Frontier.
Performance Impact
We are going to introduce a lot of information to Ebury Database, so we need to think about the performance problems of each batch.
We are going to use staging platform to test this kind of things too.
Related to this RFC we are not going to have any performance problem due to kafka connect or data consuming from Salesforce.
Developer Impact
When we start the data migration by batches developers need to start thinking that FP information is going to be on the Ebury environment and if they need to hide it or not.
Data Consumer Impact
For now all the information is going to be hidden and not exposed in any case.
Deployment
Deploy a new staging environment for FP with the proper obfuscated database.
Dependencies
The only dependence is with devops to be ready to expose the data to Kafka.