Kafka Standards and Patterns
An asynchronous event-driven architecture, underpinned by Apache Kafka, has been selected as an approach to support the transition from an Ebury legacy architecture to a desired target architecture (Ebury 2.0).
Background
Ebury technology architecture has expanded in size and complexity over many years. The evolution of its systems have centered around a few key custom applications that have become difficult to adapt to rapidly changing business needs and increasingly complex to maintain.
The Ebury 2.0 blueprint documents the business drivers in detail and concludes a decoupled, secure and robust architecture, based on event-driven design, will deliver the technical agility required to meet business needs.
Solution
Document and agree, with engineering, the Ebury Apache Kafka standards & patterns as a foundation for Ebury 2.0 architecture.
Apache Kafka Overview
Apache Kafka is known as a ‘distributed commit log’ or as a ‘streaming platform’. As a streaming platform Apache Kafka is designed to support low-latency high data throughput, fault tolerant publish/subscribe based data pipelines that are capable of processing high volume event streams in real-time. Moreover, Apache Kafka is also very capable of managing long term storage, although consideration should be taken when deciding the data retention policy.
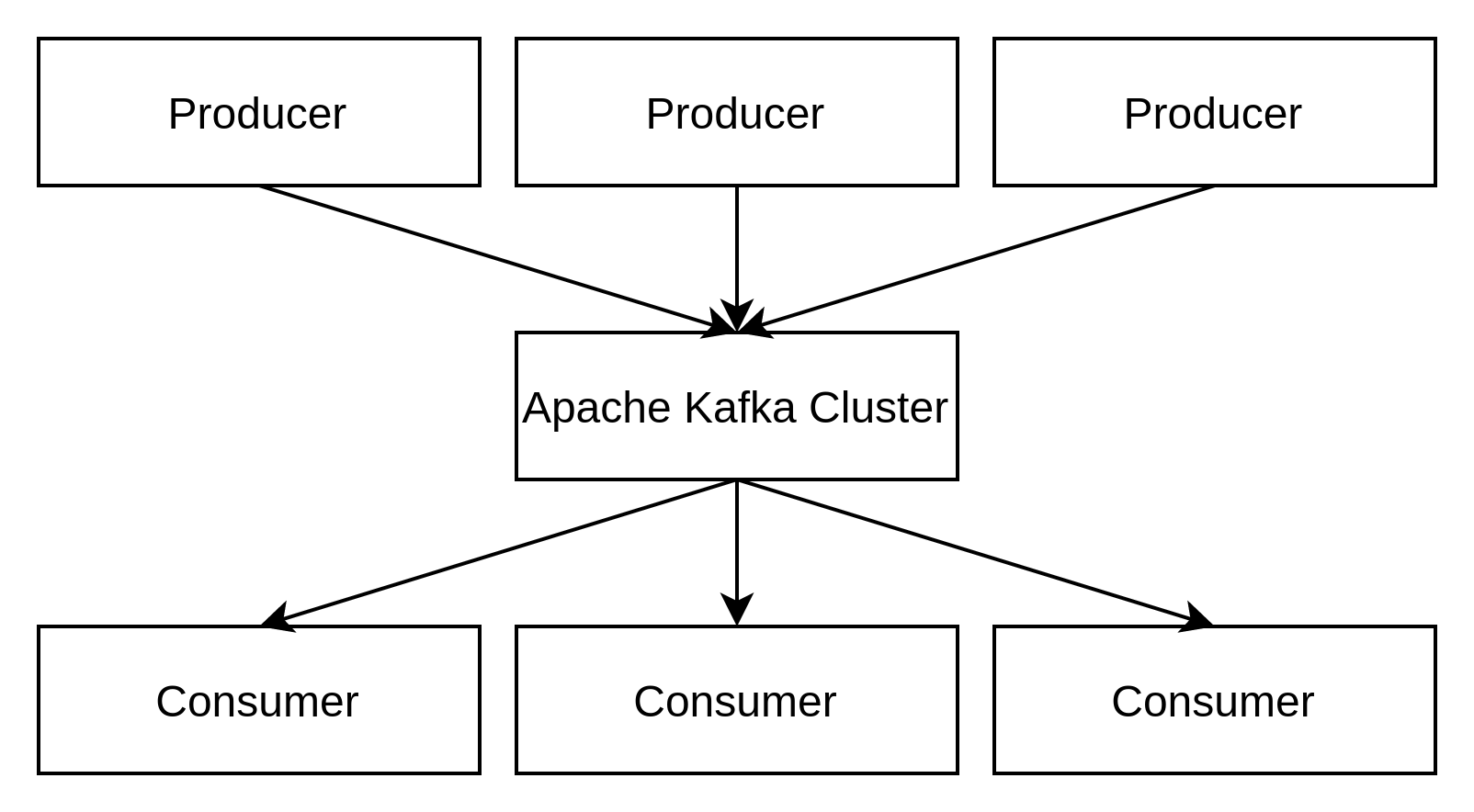
A simplified view of Apache Kafka is:
-
There are processes that publish messages to Apache Kafka (producers)
-
The messages are stored in a log and categorised into topics
-
Processes subscribe to topics and consume the published messages (consumers)
-
Apache Kafka operates as a cluster with component servers known as brokers
Kafka Standards
This section will focus on the Apache Kafka standards that are associated with event handling.
Topics
Topic replication
Core to Kafka’s fundamentals are topics, each configurable with their own retention, partition and compaction configuration. Typically the messages contained within Kafka topics fulfill multiple business processes e.g., account opening generates a text notification and separately generates an opening account statement - therefore it’s not uncommon that topic configurations vary depending on the use case. However, it is not possible to configure one Kafka topic to have varying configurations dependent on the Consumer and therefore data must be replicated to an alternative topic that is configured with the desired settings.
When assessing whether a replica topic is required the following considerations should be made:
-
General data principle - minimize replication and duplication of data, unless for clear performance or resilience benefits.
-
Topic configuration - All messages contained within a topic must have the same configuration across all consumers of that topic. If use cases requirements dictate that data must be stored/consumed with a variance in configuration it will be necessary to replicate the topic.
-
Retention Policy - Messages contained within a topic are restricted to the same retention policy. If there is a requirement for data to be stored with a shorter retention period it becomes necessary to replicate the topic.
-
Permissions - All messages contained within a topic must be provisioned with the same access control. To appropriately manage the security topic controls a topic(s) may be replicated and transformed into specific views, each with different levels of access.
-
Data Enrichment - When sourcing from an Kafka topic that contains data from a 3rd Party, there may be a requirement to manipulate/transform the data before posting it to a downstream system. From an end-to-end reconciliation perspective it is critical that data can be followed from the point of data acquisition to final hand-off - break down the process logically (Extract, Transform, Load) rather than apply transformations directly against the data source (see topic naming for more detail)
Topic naming conventions
If you need to, you can get familiar with Kafka topics here.
Topic names are defined when creating the topic and cannot be changed once created, it is therefore important to get the naming right the first time.
Before naming a topic please be familiar with Ebury blueprints that touch on the service communication patterns topic:
- Technology Strategy
- Asynchronous Command Interface Pattern
- AsyncAPI for documentation in Events based architecture
- Ambassadors
- Loosely Coupled Asynchronous Microservices
- Event -Driven Architecture Patterns (CDC topics)
- Event Standard
- Kafka Standards and Patterns
- Orchestration and Choreography
- Reference Data Service Pattern
- Schema Evolution
Consider the following for topic names:
Valid character set
is the ASCII alphanumerics, ‘.’, ‘_’, and ‘-’ (ref)
No names that will change
For example, no team name, topic owner, service name, product name, or consumer name. No names of producer(s) and consumer(s).
(Some of these suggestions come from this blog post.)
No redundant information
Don't add information into topic names that can be obtained from the source of truth
- message schema ⇨ the producer service code in the lack of a schema registry
- partition count, replication number ⇨ Kafka Metadata API
- consumer or producer service names ⇨ declare consumers and producers of a topic in the ebury-manifests repo using env variable names
KAFKA_CONSUMER_TOPIC_*andKAFKA_PRODUCER_TOPIC_*(see example)
Suggested topic name structure
<message type>.<dataset name>.<data name>
- snake_case names are recommended (vs. camelCase or lisp-case)
message typeeventsprivate- data that has limited scope and/or life-span tied to a specific service (this seemingly breaks the "no service name" rule, however the ephemeral nature of data in these topics makes them replaceable with another topic)
commands- Command events (see command-reply async comms pattern and this blueprint)dataset name- this provides a logical grouping of topics, for example by business domain, and can also help to avoid name collisions
data nameorthing- analogous to a table name in a RDBMS
version tagsuffix- in the rare, unavoidable case of not compatible message schema change, you may want to produce the new message format to a new topic
- mentioning brand or customized deployment names (e.g
ebury-emp) is unnecessary if those deployments can use their dedicated Kafka cluster
See the ansible-playbook-kafka-topics repo for examples, or suggestive names in this table:
| Name | Description |
|---|---|
events.payments.beneficiary |
Beneficiary domain events |
events.payments.beneficiary.v2 |
Beneficiary domain events after breaking change in message schema |
commands.payments.beneficiary |
Command events to create/update beneficiaries |
private.payments.gpi_tracker_interface_errors |
A debug queue*, retry or dead-letter topic meant to be produced and consumed only by the gpi-tracker-interface service, with heterogeneous messages in the topic distinguished by a Kafka header attribute, for example |
private.payments.gpi_tracker_gateway_bank_account_entry_errors |
A debug queue*, retry or dead-letter topic meant to be produced and consumed only by the gpi-tracker-gateway service, with homogeneous messages (only failed BAE CDC records) |
*debug queue:
- Even though we discourage the use of dead-letter topics (due to the complexity, extra tooling needed in handling these topics), writing failed messages along with some context (exception stack trace) to an error topic is useful when troubleshooting situations in the production environment where very limited information is available in logs due to sensitive data, but a designated Ebury staff can access the information in the error topics and aid the troubleshooting.
Topic Data Retention
Data retention should align to Ebury data retention policy where appropriate, and meet business needs. Typically data stored in topics that isn’t required for infinite storage is stored for 7 days, however, where there is a clear business benefit data will be held indefinitely.
Partitions
A topic has a commit log that can be split into multiple partitions so that it can be distributed – this provides scalability and resilience. Producers write to the commit log and consumers read the commit log (increasing partition numbers can increase overall data throughput). Consider if only a single partition was possible in a kafka topic - performance, resilience and scalabilty would be very limited, hence why multiple partitions are configurable (there is a cost for adding partitions). Partitions could be added if a producer was producing events faster than a consumer could consume but adding partitions along would not increase throughput if only a single consumer was consuming off of multiple partitons. Consumer groups are a collection of consumers that consume off of partitions to increase throughput - one consumer per partition within a consumer group. 5 partitions and five consumers would potentially increase throughput (depending on use case) but it's worth considering the end point.. can that endpoint manage the data throughput?
Partitions and Keys
Kafka messages typically contain a key associated with the value, for example, a bank account number key and an account related value. Kafka uses a hash algorithm to assign a key to a partition so that all messages with a specified key are routed to an allocated partition (a partition could change if a rebalance occurred). Another advantage of assigning keys to a topic partition is ordering - Kafka can guarantee a message is consumed in the same order in which a message is produced, if a key is provided. If a key isn’t provided (null), then instead, a message is allocated to a partition on a round-robin basis. If consumer ordering is important, use a key and if it isn’t a null value is viable.
Kafka manages the partition load balancing automatically but there may be circumstances in which the partition assignment needs to be customised due to a ‘hotspot’. A hotspot could occur if, for example, payment messages were keyed on an account number but one account had millions of transactions whereas other accounts did not – another good example is to think of twitter feeds that are balanced over partitions but a celebrity has a huge volume of followers, in this situation a custom key is needed and there are different approaches available.
Message Ordering
Before implementing message order guarantees it’s important to understand what level of guarantee is required. Will a topic be required to be globally ordered or can it be ordered by a key (as described in the section Partition and Keys)?
If a topic requires global ordering (topic level) the topic must then be configured with a partition of 1, given that ordering guarantees are at partition level. However, if the requirement is for a keyed order to be partitioned (such as the example above) then an explicit key should be defined.
If message ordering is absolutely critical then the following parameter must be configured max.in.flight. requests.per.connection=1 - disables multiplexing (sending multiple streams of information over one connection) and by doing so eliminates messages being stored out of order in the event of a retry. This configuration severely impacts performance and therefore careful consideration must be taken prior to implementation.
Finally, within the Consumer, the messages must be processed synchronously rather than by processing them through an asynchronous thread pool, this will ensure that messages are processed in the order that they are received from Kafka.
Partition Capacity planning
Choosing the correct number of partitions for a topic is the key to achieving a high degree of parallelism with respect to reads and writes, as well as to an evenly distribute load (which is a key factor to obtaining good throughput).
To identify the optimal number of partitions, an estimation must be made based on the desired throughput of producers and consumers per partition:
Partitions = max(NP, NC)
where:
-
NP is the number of required producers determined by calculating: TT/TP
-
NC is the number of required consumers determined by calculating: TT/TC
-
TT is the total expected throughput for our system
-
TP is the max throughput of a single producer to a single partition
-
TC is the max throughput of a single consumer from a single partition
To utilise the above calculation, non-functional requirements must be available to provide an accurate capacity view. It is important to consider that adding partitions is not straightforward as a re-balancing partitions process occurs which will impact performance during the re-balance and create potential for operational failings as well as unintended data processing issues – these issues can be avoided but remember adding partitions can be complex. An alternative is to over estimate but this isn’t the answer either as partition come with a cost to the broker and ultimately add load to the replication process too (resilience). In general, follow the above equation but add caution as to not under estimate – as the Kafka ebury implementation matures this process will become easier.
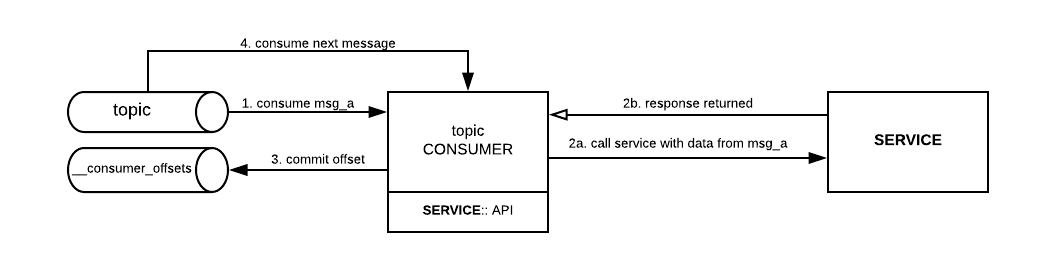
Committing Offsets
By default Kafka consumers are configured to auto commit their offsets as soon as they have received a message, for a large majority of use cases this behavior is acceptable however when utilising Kafka as a message queue which feeds downstream systems, it is often important to understand that the consumed message has been processed correctly before committing the offset to enforce delivery guarantee.
enable.auto.commit: false
The auto commit property is configurable per consumer, by changing this property the Offsets can be manually committed once the processing has taken place and a successful response has been returned by calling the commitSync() class. Manual Commits provide more control for engineers when creating consumers but it’s worth considering that an application would be blocked until the broker responds.
The diagram below outlines a standard flow for consuming messages and committing the subsequent Offset.
Asynchronous Commit
Whilst the manual commit provides control over a consumer commit procedure the synchronous blocking is a negative – asynchronous commit can overcome that specific issue, however, it will introduce another. Asynchronous commits will not retry if a broker doesn’t respond (synchronous calls will retry) – total ordering could be interrupted if during a retry, a more recent message was committed and then the older message succeeded. There are strategies to overcome this issue too, but what’s most important is that the use case is understood and the appropriate commit approach is applied.
Max.poll.interval.ms
The default value is 5 minutes – this property is a fail safe and not to be used to compensate for a inefficient consumer – if a consumer isn’t operating correctly is should be investigated to see if it’s appropriate.
Commiting offsets isn't a uniformed mechanism in which the same approach works for all use cases - each use case must be considered carefully when commiting an offset. However, applying multiple approachs for identical use cases is also unhelpful and therefore the engineering teams should discuss the approaches available and agree principles to follow - review the principles as the kafka implementation matures.
Exactly Once (Effectively Once)
When processing data through Apache Kafka there is potential for data to be duplicated (as with all distributed systems). Apache Kafka provides certain guarantees for it’s events streams to avoid duplicates – exactly once, or another way to consider it is ‘effectively once’ because duplicates will occur but Kafka handles them with the following approaches:
Kafka Streams
The most simplistic of the three concepts to configure, by setting the following parameter within Kafka Streams:
exactly.once=true
Kafka Streams therefore ensures that exactly-once semantics is enforced within the application.
A detailed explanation of how Kafka Streams achieves exactly-once is outlined here: https://www.confluent.io/blog/enabling-exactly-kafka-streams/
Idempotent Producer
With the release of Kafka 0.11, Apache have introduced an ‘idempotent producer’ which allows producers to enforce idempotence when publishing messages. By assigning the following parameter in the producer configuration:
enable.idempotence=true
Kafka will assign a sequence number to each batch of messages, these sequence numbers will then be persisted in the replicated log and used by the broker to dedupe any duplicated messages sent. In the event of a leader broker failing, another broker within the cluster will take on the leader responsibilities and will read from the replicated log to identify whether a message that has been re-sent is a duplicate.
SQS FIFO implements excaltly once on a per queue basis only; messages recieved from a producer are held for 5 minutes and then deleted, therefore any duplicated messages recieved after 5 minutes would pass through unless additional logic was built in to a consumer.
Atomic Writes
Kafka fully supports atomic writes across multiple partitions through its transactions API. This functionality allows a producer to send a batch of messages to multiple partitions such that either all messages in the batch are eventually visible to any consumer or none are visible to the consumer.
With this feature it is therefore possible to commit the consumer offset in the same transaction along with the data that has been processed, allowing end-to-end exactly-once semantics.
Kafka Patterns
Message Queuing
Message queuing is a point-to-point style messaging pattern, where the message will be removed from the queue once it has been consumed by any of its consumers.
Apache Kafka can be used to reliably process streams of data into a topic, which can be replicated across the cluster providing safe and consistent data storage. By committing processed message offsets back to Kafka, it is relatively straightforward to guarantee ‘at-least-once’ data processing.
The one limitation however is that it’s only possible to commit all messages up to a given offset, as opposed to acknowledging messages on an individual basis.
Kafka as a message queue example:

Log-based approach (Kafka) compared to traditional messaging based services e.g., SQS have trade-offs – with Ebury in mind there is also a level of maturity to consider with Kafka – a debate is required. However, broadly speaking Kafka provides a number of data guarantees (strict ordering), long term storage for replay, as well as high through-put when compared to traditional messaging systems.
Another consideration is that Kafka nodes can share the load of consuming topics via allocating a partition per consumer, but if a message is slow to process in a partition then a form of head-of-line blocking can occur - thus, in situations where messages are expensive to process and you want to parallelise on a message-by-message basis then a traditional message broker is more appropriate.
Publish/Subscribe
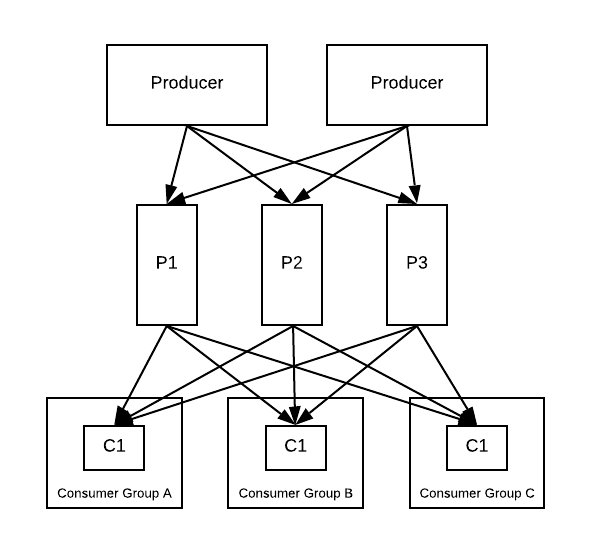
Publish/Subscribe is a messaging pattern, where senders of messages (publishers), do not program the messages to be sent directly to specific receivers (subscribers) but instead categorise data into classifications of data (without any knowledge of which subscribers may be listening).
With consumer groups within Kafka, messages are evenly load balanced between consumers, this process is known as a queuing model. As a direct contrast to this model, a publish/subscribe can be achieved by ensuring that each consumer belongs to a different consumer group, the result of this is that all messages will each be consumed by every consumer client.
Publish Subscribe with Kafka example:
Event/Data Store
A data store is a repository for persistently storing and managing collections of data such as (but not restricted to) data from an end user database or data from a file/document. Data stored within a data store may be structured, unstructured or in an alternative format.
Through Apache Kafka a Kappa Architecture software architecture pattern can be achieved where rather than using a relational database such as SQL or a key-value store like Cassandra, the canonical data store is an append-only immutable log. From the log, data is streamed through a computational system and fed into auxiliary stores for serving.
With Kafka’s ability to replay data from a given point in time the need for a ‘one size fits all’ data model is eliminated. Auxiliary stores act as a serving layer to the end user and can be dropped and recreated by simply reprocessing the Kafka topic.
The below example describes an event life cyle for data management purposes – not a core Ebury use case at the moment but an important concept to consider nonetheless (diagram walk through below):
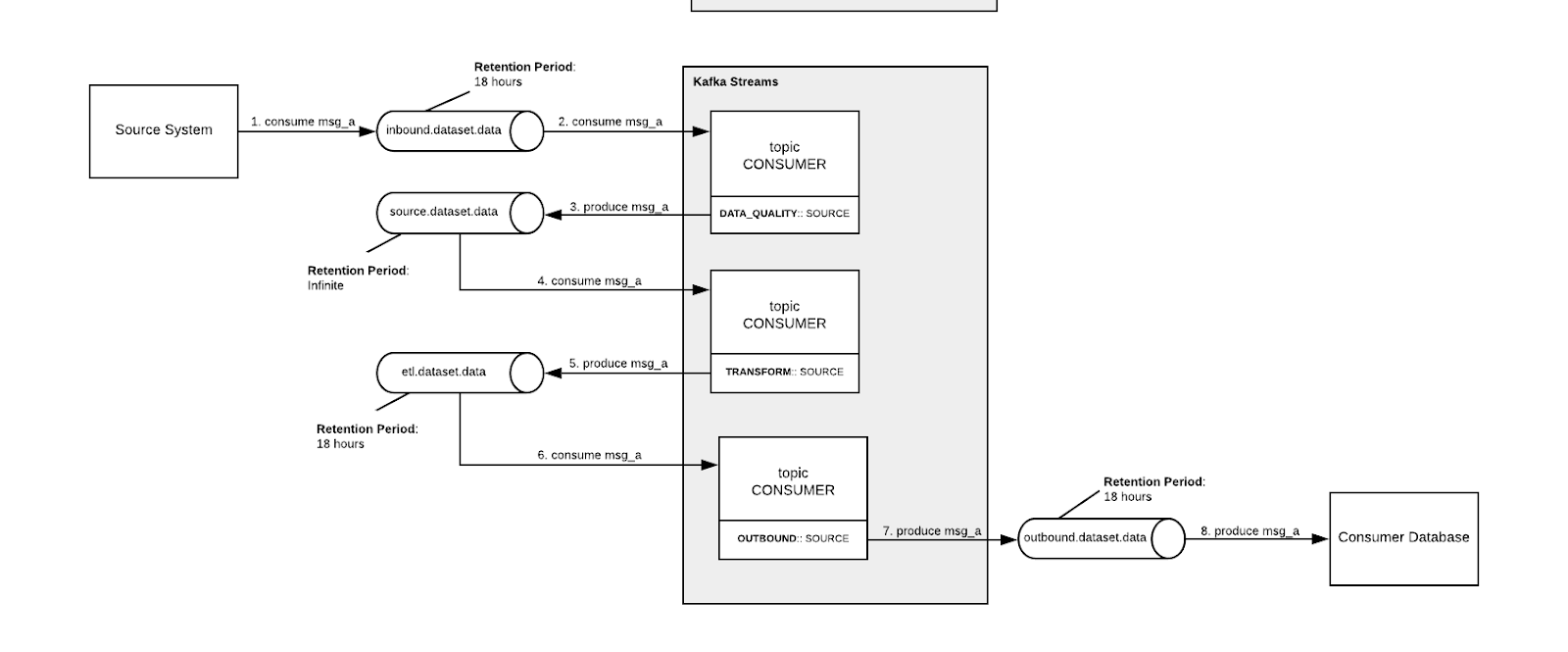
Diagram walk through:
Inbound topics will be utilised to store raw data in the Kafka cluster, the recommendation is that this topic is persisted for a moderate period of time allowing sufficient time for any potential debug/analysis however should be truncated for processing the following execution.
Source topics will contain data which has been staged and validated, this data will be persisted for a much larger period of time (depending on replay requirements) and will be used when Ebury require a new or modified set of data from the consumed data source. For analytics purposes, all data which is deemed necessary for reporting purposes, will be maintained in line with data retention policy.
ETL topics will be used for any data which has been transformed, joined or modified in any way, the recommendation is that this topic is persisted for a moderate period of time allowing sufficient time for any potential debug/analysis however should be truncated following execution.
Outbound topics will be used to store any data which is leaving the Kafka cluster. The retention period on this topic is completely dependent on the windowing required for processing.
Finally, custom consumers will be produced to assess the quality of the inbound data before they are committed to source topics. The service will utilise schema registry to validate structural changes and will include a built-in exception checks which will drop messages onto a DLQ (covered in the error handling section of this document).
Error Handling
The RetriableException is an abstraction exception representing transient exceptions that might succeed if retried. Kafka Consumers and Producers could therefore automatically retry this set of exceptions if the retried property has a value greater than 0. Nonetheless, if the automatic retries are not successful or timeout, the RetriableException will be thrown to the application realm and therefore a method must be developed to deal with this exception either via adequate fail over or retry strategy.
We should manage the following two error scenarios: the consumer received a bad message and/or the consumer attempts to write to a downstream system which is down.
When the consumer receives a bad message, the consumer should not halt consumption and should therefore only commit message offsets for messages which have been successfully processed. Instead, the consumer should log an error message and/or send the bad message to a dead letter queue, which is a separate Kafka topic specifically for bad messages. By following this approach messages can continue to be committed as normal.
When the downstream system which the consumer is writing to goes down, the consumer should either exit the write operation with an exception, or continue to retry until the downstream system is back online.
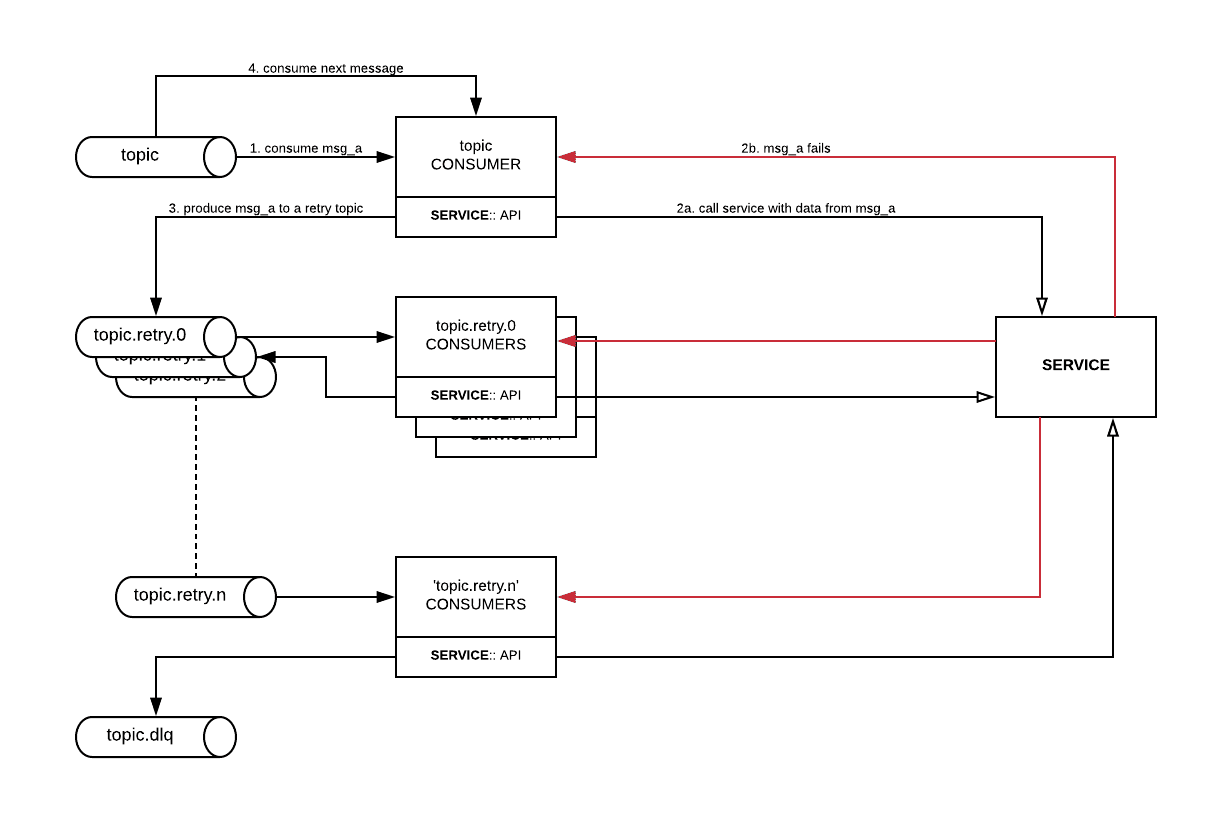
To manage failure scenarios (as outlined above), configure retry queues using separately defined Kafka topics. Using this pattern, when a consumer handler returns a failed response for a given message, the consumer will publish that message to its corresponding retry topic (consider the impact on ordering when in this scenario). The consumer handler will then return to the original consumer and commit its offset and by doing so consumer success is split from a successful service response. By following this pattern the expected response from the consumer is true therefore all exceptions are handled elsewhere in separate topics.
A separate group of retry consumers will therefore be provisioned to read from their corresponding retry queue, these consumers will behave identical to those in the original architecture however they will consume from a different Kafka topic. By provisioning a number of these retry topics, with a different set of listeners consumer to each topic, the ability to implement a circuit breaker approach means messages will retry a send request at various intervals until a total of ‘n’ attempts have been completed where the message will eventually be written to a dead letter queue (DLQ).
If a consumer of the last retry topic does not return success then it will publish the message to the DL topic which will be manually monitored and maintained by an operational team.
The diagram below shows a typical error message flow from data acquisition to being committed to the DL topic:
Summary
This document has covered key areas of discussion involved in the setup and interaction with Apache Kafka for event driven architecture. There are other considerations beyond what is written in this document and therefore this document will continue to elaborate overtime, as and when challenges appear that require an undocumented approach or if an existing approach doesn't meet the needs of a use case. It's important to recognise this document as a set of guiding principles - not to be ignored but equally not to be followed without considering the impacts of a delivery. Apache Kafka provides a resilient and saleable platform with the ability to deliver high-throughput of events. Apache Kafka provides the capabilities to tackle common data guarantee issues that occur in a distributed system but it's important to recognise the guarantees are not all pre-configured and that one single approach will not resolve all possible data guarantee issues.